우테코 - 지하철 미션 회고
지하철 미션을 진행하면서 있었던 과정을 회고해보자

밀린 회고들을 방학이 돼서야 쓰게 됐다.. 지하철 미션 때부터 번아웃이 온 거 같더니 회복할 틈도 없이 미션, 글쓰기, 테코톡, 근로 등에 치여 엄청 바쁘게 살아온 것 같다. 뭔가 엄청나게 이끌려서 수동적으로 산거 같은 느낌이 든다. 레벨 1때부터 느꼈지만 역시 체력이 정말 중요하다고 느꼈고 그 체력이 나는 바닥임을 느꼈다. 레벨 3때부터는 좀 더 체계적으로 루틴을 잡고 그 루틴을 잃지 않도록 절대적으로 노력해야겠다.
이번 지하철 미션은 하기 전부터 겁을 먹었던 녀석이다. 우테코 최종 코딩 테스트 연습을 할 당시에도 다른 여러 문제를 풀었지만 이 문제만은 보기 전부터 풀기 싫어 PASS를 했으니.. 실제로 미션에 들어간 후 첫날은 도메인 설계에만 시간을 다 썼지만 실패하고 집에 가서 생각을 해왔다. 실패를 한 요인을 분석해 보면 도메인을 짜는데 자꾸 나중에 성능을 생각하다 보니 쓸데없는 사족이 들어가게 되었고 그 사족들이 하나둘씩 붙다 보니 뭘 만들고 있던 건지 복잡해져 머리가 자꾸 꼬였던 것 같다.
왜 코드 구현과 리팩터링 단계를 따로 두는 건지 이전에는 몰랐지만 이번에 확실히 알 것 같다. 글도 한 번에 쓰는 습관이 있었는데 한 번에 쓰려니 부담감이 엄청 커 스트레스를 많이 받았다. 오늘 안에 이걸 다 끝내야 된다는 강박감 때문에 밥도 안 먹고 쓰고 억지로 내용을 만들어 쓰고 그러다 보니 몸에 또 무리가 오고 반복한 게 아닐까. 이처럼 한 번에 모든 걸 하려는 건 좋지 않은 것 같다. 우리는 기계가 아닌 사람이니까… 근데 가끔 그런 괴물들이 존재하곤 하더라..
이제 사족은 끝내고 미션 회고를 해보자!
Repository, DIP 적용
이전 미션까지는 Dao만 사용하고 Repository의 필요성이 느껴지지 않아 사용하지 않았지만 이번에는 도입하지 않으면 Service에서 하는 역할이 매우 많아질 거라 생각하였고 그에 따라 가독성 저하 및 책임 분리가 잘되지 않을 것이라 판단해서 적용하게 되었다. 만약 적용하지 않았다면 2번째 코드처럼 되었을 것이다. Dao vs Repository의 차이가 궁금하면 다음 글을 한번 보고 오자!
//Repository 적용시
public Long addSection(final SectionCreateDto sectionCreateDto) {
final Line line = lineRepository.findById(sectionCreateDto.getLineId());
final Station upStation = stationRepository.findById(sectionCreateDto.getUpStationId());
final Station downStation = stationRepository.findById(sectionCreateDto.getDownStationId());
final Section section = Section.of(upStation, downStation, sectionCreateDto.getDistance());
line.add(section);
lineRepository.updateLine(line);
return line.getId();
}
//Repository 적용x
public Long addSection(final SectionCreateDto sectionCreateDto) {
final LineEntity lineEntity = lineDao.findById(sectionCreateDto.getLineId())
.orElseThrow(() -> new IllegalArgumentException("존재하지 않는 노선 이름입니다."));
final List<Section> sortedSections = getSortedSections(sectionCreateDto.getLineId());
final Line line = new Line(lineEntity.getId(), lineEntity.getLineName(), Sections.values(sortedSections));
final StationEntity stationEntity = stationDao.findById(sectionCreateDto.getUpStationId())
.orElseThrow(() -> new IllegalArgumentException("해당 이름의 역이 존재하지 않습니다."));
final Station upStation = new Station(stationEntity.getId(), stationEntity.getStationName());
final StationEntity stationEntity = stationDao.findById(sectionCreateDto.getDownStationId())
.orElseThrow(() -> new IllegalArgumentException("해당 이름의 역이 존재하지 않습니다."));
final Station downStation = new Station(stationEntity.getId(), stationEntity.getStationName());
final Section section = Section.of(upStation, downStation, sectionCreateDto.getDistance());
line.add(section);
sectionDao.deleteAllByLineId(line.getId());
sectionDao.insertAll(line.getSections().stream()
.map((section) -> new SectionEntity(
line.getId(),
section.getUpStation().getId(),
section.getDownStation().getId(),
section.getDistance()))
.collect(Collectors.toList()));
return line.getId();
}
private List<Section> getSortedSections(long lineId) {
final SectionsSorter sectionsSorter = SectionsSorter.use(mapToSections(lineId));
return sectionsSorter.getSortedSections();
}
그리고 현재 계층형 아키텍처를 사용하기 때문에 도메인 계층이 영속성 계층에 의해 크게 영향을 받는다. 여기서 도메인과 영속성 간의 결합을 줄여주기 위해 추가적으로 DIP(Dependency Inversion Principal) 를 적용했다. DIP는 의존 역전 원칙으로 고수준 모듈이 저수준 모듈의 구현에 의존해서는 안 되고 저수준 모듈이 고수준 모듈에서 정의한 추상 타입에 의존해야 된다는 것이다.
- 고수준 모듈: 어떤 의미 있는 단일 기능을 제공하는 모듈
- 저수준 모듈: 고수준 모듈의 기능을 구현하기 위해 필요한 하위 기능의 실제 구현
고수준 모듈이 저수준 모듈에 의존할 때 문제점은 다음과 같다. 쿠폰을 이용한 가격 계산 모듈(고수준)이 개별적인 쿠폰(저수준) 구현에 의존하게 되면 아래처럼 새로운 쿠폰 구현이 추가되거나 변경될 때마다 가격 계산 모듈이 변경되는 상황이 발생한다.
public int calculate() {
...
if (someCondition) {
CouponType1 type1 = ...
} else {
// 쿠폰2 추가에 따라
// 가격 계산 모듈 변경
CouponType2 type2 = ...
...
}
}
이런 상황은 프로그램 변경을 어렵게 만드는데 우리가 원하는 것은 구체적인 사항(저수준)이 변경되더라도 고수준 모듈이 변경되지 않는 것이다. 이것을 의존 역전 원칙으로 인해 해결할 수 있다. 어떻게 할 수 있을까?
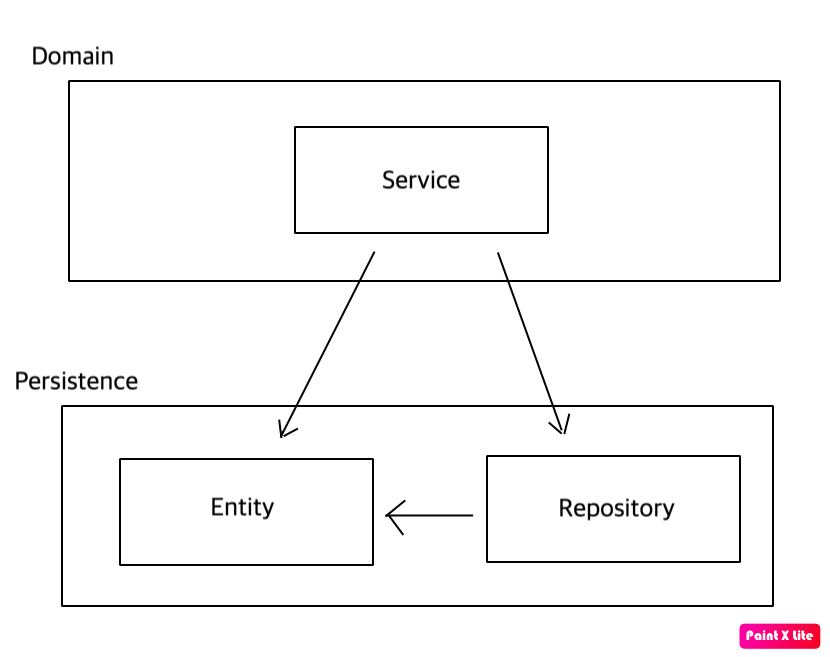
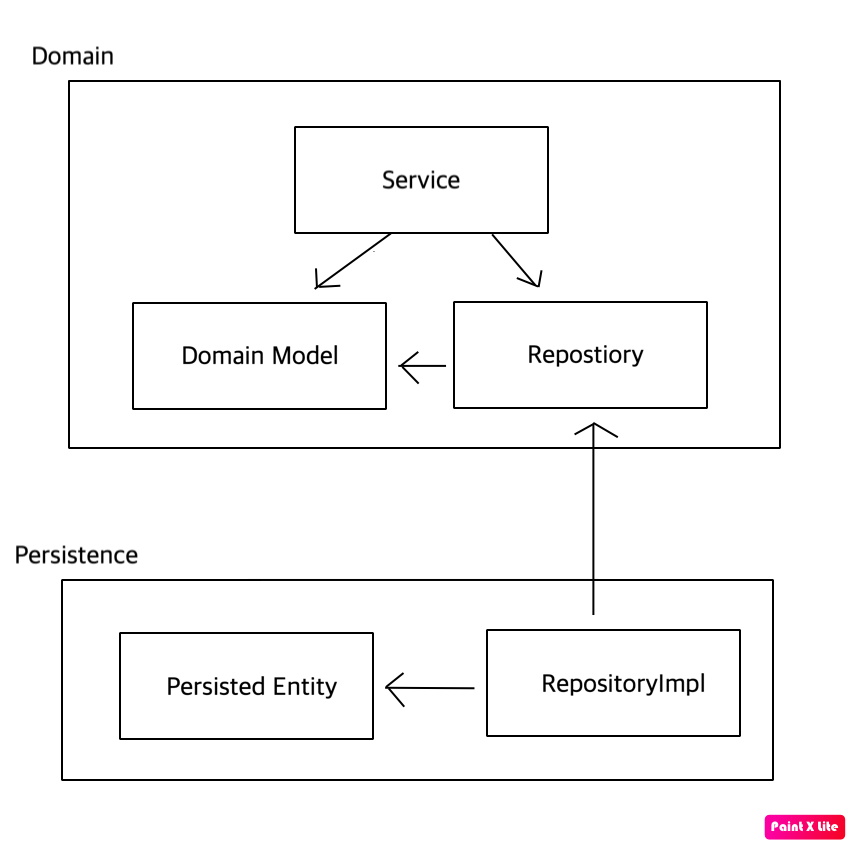
일반적으로 위와 같이 도메인에서 영속성 쪽으로 의존하고 있을 것이다. 여기서 의존성을 역전 시키려면 Repository를 인터페이스로 바꾸고 Domain 패키지로 옮긴다. 그러고 나서 실제 구현체를 영속성 계층에서 구현하게 하면 의존성을 뒤집을 수 있게 되고 영속성 계층에서 수정이 있더라도 도메인 계층에는 영향을 주지 않게 된다.
DTO 변환위치?
우리는 Controller와 View 사이 데이터를 주고받을 때 별도의 DTO를 사용해서 통신한다. 도메인 객체를 View에 바로 전달할 수도 있지만 DTO를 사용함으로 써 주요 비즈니스 규칙을 외부에 노출시키지 않을 수 있고 필요한 부분만 넘길 수 있다. 또한, View와 의존하지 않고 순수하게 도메인 로직만 담당할 수 있게 된다.
DTO를 사용한다면 이 DTO와 Domain 간 객체 변환 위치가 있을 것이다. 과연 어디에 있는 게 적절할까?
Service 계층?
우선 서비스 계층에서 변환한다고 생각해 보자. Controller에서 DTO가 넘어올 것이고 그 DTO를 Service 메소드의 파라미터로 받을 것이다. 그리고 그 DTO를 domain으로 객체 변환이 일어나게 된다. 이 방법의 단점은 무엇이 있을까? 서비스에서는 View에서 Controller로 넘긴 DTO를 그대로 사용하기 때문에 특정 Controller와의 결합도가 높아진다. 그래서 해당 서비스의 재사용성이 낮아진다는 단점이 있다.
Controller 계층?
그럼 컨트롤러에서 변환하면 어떨까? 응답할 때를 생각해 보자. 도메인 모델이 컨트롤러까지 넘어오게 되고 여기서 Dto로 변환하는 작업이 일어날 것이다. 어떤 문제점이 있을까? View에 반환될 필요가 없는 데이터까지 객체(Domain Model)에 포함되어 표현 계층까지 넘어 온다. 또한, 여러 Domain Model을 조합해서 DTO를 만들어야 될 경우 결국 응용 로직이 컨트롤러에서까지 사용될 수 있다.
또한, 요청할 때 View에서 전달받은 정보만으로 Domain 객체를 구성할 수 없을 때도 있을 것이다. 예를들어, ID만 받은 경우 ID외의 정보를 Repository를 통해 조회하고 나서야 Domain을 구성할 수 있다. 그럴때는 Controller에서 바로 Repository를 접근하는 것이 맞을까?
그렇다면 나는 어떤 선택을 했는가?
Controller에서 변환 시 여러 문제점들과 Presentation 레이어에서 우리가 다루는 중요한 도메인을 알고 있는 것 자체가 찝찝했다. 그리고 Tecoble에서 “여러 종류의 컨트롤러가 한 서비스를 사용하는 경우보단 보통 한 종류의 컨트롤러가 서비스를 사용하기 때문에 그렇게 엄격히 제안할 필요가 있냐는 의견도 있다. 그래서 보통 코드를 보면 서비스로 DTO 진입을 허용하되 서비스 메소드 상위에서 DTO 체크 및 도메인 변환을 하고 변환 한 후에는 도메인 만 사용하도록 구현 되어있다.” 와 같은 피드백을 보았다. 그래서 결국 Service 계층에서 변환해 주는 걸 택하였다.
하지만 여전히.. Controller와 Service의 결합도가 높아진다는 문제점이 나를 찝찝하게 만들었다 ㅋㅋㅋ
양방향 매핑
둘의 결합도를 끊어주기 위해서는 Service에 맞는 적절한 DTO를 받아 줄 수 있을 것 같다. 즉, View <–> Controller에서 DTO를 받은 후 그 DTO로 다시 Controller <–> Service 통신을 위한 DTO를 만들어 주는 것이다. 응답의 경우도 마찬가지.
@PostMapping("/members")
public void create(@RequestBody CreateRequestDto createRequestDto) {
memberService.create(createRequestDto.toServiceCreateDto());
...
}
이 부분을 적용했냐라고 하면? 적용하진 않았다. 사실 이 경우가 가장 이상적이지 않나 생각이 들긴 한다. 하지만 그만큼 비용이 엄청나다. 계층 간 통신을 할 때마다 DTO가 생성되기 때문에 매우 복잡해 보인다. 그래서 프로젝트 규모가 커지거나 분리가 필요할 때 사용하는 것이 맞지 않나 생각이 든다! 과연 레벨3 팀 프로젝트 때 적용할 일이 있으려나..? 기대가 된다 ㅎㅎ
+각각의 DTO를 하나로 통합?
초반에 CRUD 로직을 구현하다 보면 비슷한 형식의 데이터를 받기 때문에 DTO를 하나로 통합해서 사용할지 분리해서 쓸지 고민을 했던 적이 있던 것 같은데 그 이유는 바로 중복이 있기 때문이다.
public class CreateDto {
private String name;
private String email;
private String password;
...
}
public class UpdateDto {
private String name;
private String email;
private String password;
...
}
클린 아키텍처에서 중복은 나쁜 것이지만, 이 중복이 진짜 중복인지 아니면 우발적 중복인지 구분되어야 한다고 한다. 여기서 진짜 중복은 한 인스턴스가 변경되면, 동일 변경을 그 인스턴스의 모든 복사본에 적용해야하는 케이스이고 가짜 중복은 중복으로 보이는 두 코드 영역이 서로 다른 속도와 다른 이유로 변경이 되는 것을 이야기 한다. 여기서 우리가 사용하는 각각의 CRUD DTO가 현재는 중복되어 있지만 언제 각각의 사정(서로 다른 속도와 다른 이유)으로 변경될지 모르기 때문에 분리하는게 좋을 것 같다.
좋은 API 설계를 위한 방법
API 설계할 때마다 URI는 어떻게 짜고 response는 어떻게 줄지 깊게 생각해 본 적이 없어 한번 정리해보고 가면 좋을 것 같아 정리해 본다.
URI는 직관적으로
URI를 보는 것만으로도 어떤건지 바로 이해할 수 있어야 한다.
- 길게 만드는 것보다 최대 2 depth 이하로 만드는 것이 적당하다.
- /students/1
- URI에 리소스명은 동사보다 명사를 사용한다.
- 리소스에 대해서 행동을 정의하는 형태를 사용한다.
- 잘못된 예시
- HTTP Post: /getStudents
- HTTP Post: /setStudentsTeacher
- 적절한 예시
- HTTP Get: /dogs
- HTTP Post: /students/{tom}/teacher/{merry}
리소스간의 관계를 표현
리소스간에는 서로 연관관계가 있을 수 있다. 어떻게 URI로 이 관계들을 표현하면 좋을까?
- 서브리소스로 표현하는 방법
- 예를들어 학생이 가지고 있는 과목들의 목록을 표현해보면
- /”리소스명”/”리소스 id”/”관계가 있는 다른 리소스명”
- HTTP Get: /students/{studentId}/courses
- 일반적으로 소유 “has”의 관계를 묵시적으로 표현할 때 사용
- 서브 리소스에 관계를 명시 하는 방법
- 관계의 명이 복잡하다면 관계명을 명시적으로 표현할 수 도 있다.
- 예를들어 학생이 좋아하는 과목의 목록을 표현해보면
- HTTP Get: /students/{studentId}/likes/courses
- 관계의 명이 애매하거나 구체적인 표현이 필요할 때 사용
에러처리
에러 처리의 기본은 HTTP Response Code를 사용한 후, Response body에 error detail을 서술하는 것이 좋다고 한다. 예를 들어, Twillo의 Error Message의 경우 다음과 같다.
{
“status”:”401”,
”message”:”Authenticate”,
”code”:200003,
”more info”:”http://www.twillo.com/docs/errors/20003"
}
에러 코드와 해당 에러 코드 번호에 대한 상세 Error link도 제공한다. 이는 개발자나 Trouble Shooting하는 사람에게 많은 정보를 제공해서, 조금 더 디버깅을 손쉽게 한다.
API 버전 관리
API 정의에서 중요한 것 중 하나는 버전 관리라고 한다. 이미 배포된 API의 경우 계속해서 서비스를 제공하면서, 새로운 기능이 들어간 새로운 API를 배포할 때는 하위 호환성을 보장하면서 서비스를 제공해야 하기 때문에, 같은 API라도 버전에 따라서 다른 기능을 제공하도록 하는 것이 필요하다.
- api.server.com/account/v2.0/groups
- salesforce.com/services/data/v20.0/sobjcets/Account
DTO 필드가 하나인 경우 역직렬화 실패..?
평화롭게 클라이언트에서 온 정보를 @RequestBody를 통한 역직렬화를 하던 중 갑자기 역직렬화가 동작하지 않는다..? 코드에는 문제가 없고.. 뭔가 역직렬화를 하는 과정에서 문제가 생긴 거 같다. 다른 것과 비교끝에 지금 문제가 생긴 곳에서 사용하는 DTO의 필드는 한 개라는 점을 발견했고 이것과 관련이 있지 않을까 하고 찾아보았더니 인수가 1개인 생성자 사례의 모호성으로 인해 잘 알려진 문제라고 한다.
//기존 코드
@PostMapping
public ResponseEntity<Void> create(@RequestBody LineCreateDto lineCreateDto) {
final Long lineId = lineService.createLine(lineCreateDto);
return ResponseEntity.created(URI.create("/lines/" + lineId)).build();
}
public class LineCreateDto {
private final String name;
public LineCreateDto(final String name) {
this.name = name;
}
public String getName() {
return name;
}
}
왜 인수가 1개일 때는 작동하지 않을까? 인수가 1개인 생성자는 모호하기 때문에 바인딩에는 2가지 가능한 모드가 있다고 한다.
- 속성 기반: 입력은 JSON Object여야 하며, 속성은 생성자 인자와 이름이 일치해야 합니다. 속성 값은 일치하는 인자로 표시된 유형으로 역직렬화됩니다. 이 모드는 인자 수에 관계없이 모든 생성자에서 작동합니다.
// accepts JSON value like: "some text" // and serializes back to JSON String public class StringWrapper { private String value; @JsonCreator(mode = JsonCreator.MODE.DELEGATING) public StringWrapper(String v) { value = v; } // commonly serialized like so: @JsonValue public String getValue() { return value; } }
- 위임: 입력은 모든 JSON 유형이 될 수 있으며, 생성자 인자 하나(유일한)의 유형으로 역직렬화됩니다(이름은 상관없지만 유형은 일치해야 함). 이 모드는 인수가 1개인 생성자에서만 작동합니다(실제로 @JacksonInject를 사용하는 특수한 경우가 있으며 정확한 규칙은 “주입되지 않은 매개변수가 하나뿐이어야 한다”는 것입니다).
// accepts JSON value like: { "id" : "xc974" } public class IdToken { private String id; @JsonCreator(mode = JsonCreator.MODE.PROPERTIES) public IdToken(@JsonProperty(id") String id) { this.id = id; } // will serialize as JSON object with this property: public String getId() { return id; } }
@JsonCreator 같은 명시적 선언이 없을 경우 어떤 것을 쓰려는지 모호하다는 것인데 즉 “string-value” 같은 위임 모드인지 {“name” : “value”} 같은 속성 기반 모드인지 추측하려고 할 것이다. 인수가 1개인 경우 Default값이 위임 모드이기 때문에 Object 값을 기대하는 것이 아니라 String을 기대한다. 그렇기 때문에 우리가 원하는 대로 작동이 되지 않았던 것. 그냥 json으로 String을 보내면 잘 작동하는 걸 확인할 수 있다.
이를 어떻게 해결해볼 수 있을까?
- 기본 생성자 적용
- 생성자 위에 @JsonCreator(mode = Mode.PROPERTIES) 적용
- 생성자 위에 @ConstructorProperties(value = {value}) 적용
+리뷰어님께 받은 코드 리뷰에 대해 관심이 있으면 다음 PR들을 참고!
참고:
- REST API 이해와 설계 - #2 API 설계 가이드
- https://cowtowncoder.medium.com/jackson-2-12-most-wanted-3-5-246624e2d3d0
*틀린 부분이 있으면 언제든지 말씀해 주시면 공부해서 수정하겠습니다.