수백 개의 분산 서비스에서 Observability 시스템 구축하기
Building an Observability system across hundreds of distributed services

현대의 소프트웨어 기반 기술들이 가상화 및 추상화를 기반함으로써 많은 문제들을 해결할 수 있었지만 기술의 기반 환경이 점점 가상화, 추상화되고 있다는 점은 역으로 문제 발생 사이를 추적하기 더 어렵다는 문제점이 발생할 수 있다.
수시로 업데이트되는 MSA 상의 서비스와 의존관계, 동적으로 변경되는 인프라, 단일 요청을 처리함에도 불구하고 여러 개의 예측할 수 없는 네트워크 홉을 통과해야 하는 구조, 높은 Cardinality를 가진 지표 등은 기존의 일반적인 모니터링 기반의 문제 탐색을 어렵게 한다.
기본적인 시스템과 이미 경험한 장애 케이스를 탐지하는 수준의 모니터링을 넘어서 겪어 보지 못한 새로운 현상에 대한 가시성을 제공하고 원인에 대한 질문에 답할 수 있는 시스템을 Observability라고 한다.
좋은 로그가 뭘까?
로그란 무엇일까? 우리가 작성한 로직에 문제가 없다고 하더라도 외부 연계 시스템에서 잘못된 응답을 반환하거나 인프라 레벨의 문제가 발생해 로직이 우리의 의도대로 동작하지 않을 수 있다. 그렇기 때문에 로직을 작성하는 단계부터 로그를 잘 기록하도록 준비해두어 문제가 발생했을 때 우리의 시스템이 어떻게 동작했는지 기록으로 남기는 것은 중요하다.
MSA 아키텍처의 도입 등으로 인해 요청이 분산되어 처리하면서 우리의 시스템이 어떻게 동작했는지 확인하는 것은 더욱 어려워졌다. 과연 로그를 잘 남긴다는 게 뭘까?
우선 Spring Web 의존성만 추가한 프로젝트를 기반으로 작성한 API를 호출했을 때 보이는 기본 로그는 다음과 같다.

로그가 기록된 시간, 로그 레벨, 프로세스 id, 요청 처리에 사용된 스레드, 로그를 남긴 코드 위치가 나오는 걸 볼 수 있다.

하지만, 여기서 새로운 API를 하나 더 추가하고 두 개의 API를 섞어 호출한다면 어느 API 호출에 의해 로그가 남았는지 알 수 없다. 이 문제를 해결하기 위해 로그를 남길 때 API 정보를 포함시켜 기록을 남길 수 있다. 또한, 사용자별 API 호출 횟수를 알고 싶으면 사용자 id가 로그에 포함되도록 하면 된다.
즉, 해당 요청을 처리할 때 필요한 맥락 정보를 로그에 추가하면 요청이 처리된 당시 시스템 상황을 이해할 때 도움이 된다.

또한, 에러 원인을 분석하고자 Stacktrace도 로그로 남기고 원인 분석에 사용할 수 있다. 하지만, Stacktrace 로그가 많이 남게 된다면 어느 요청에 의해 남게 된 Stacktrace 인지 알 기 어려울 수 있다. 예외가 발생했을 때를 대비해 요청당 식별자(Trace Id) 를 하나 발급해두고 모든 로그에 요청당 식별자를 남겨두면 상황을 이해하는데 도움이 된다.

이때, 데이터 분석가분께서 유저별로 경험하는 API 별 평균 응답 시간을 알기 위해 데이터를 추출할 수 있는지 물어보신다면? API와 사용자 Id를 로그에 남겨두었으니 쉽게 할 수 있을 거 같지만 로그를 파싱 하려고 저장된 로그를 살펴보니 기록하는 순서에 일관성이 없다.

이를 위해 로그를 정형화해서 저장해두는 것이 필요하다. 로그가 JSON 형식으로 정형화되어 저장되므로 로그에 추가되는 항목이나 기록되는 항목의 순서가 변경되더라도 걱정할 필요가 없다. 또한, JSON 형식은 널리 사용되는 데이터 형식이므로 외부 도구와 연계하여 로그 검색 시스템을 만드는 것도 용이하다.
어떻게 분산 추적을 할 수 있을까?
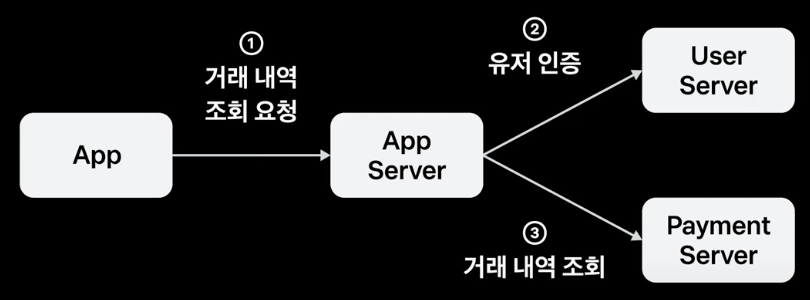
MSA 환경에서는 어떻게 로그를 잘 남길 수 있을까? 사용자가 App을 통해 거래 내역을 조회하는 상황을 가정해 보자.
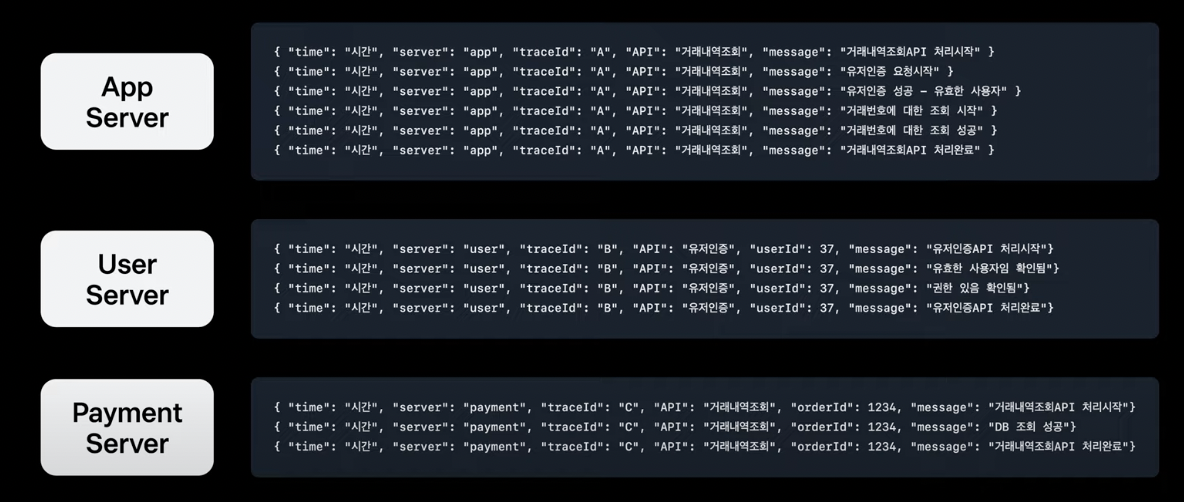
위에서 말한 것처럼 로그가 JSON 형태로 정형화되어 있고, 같은 맥락의 로그는 동일한 Trace Id로 추적, User 서버는 UserId, Payment 서버는 OrderId를 로그에 남겨두는 등 좋은 로그의 형태처럼 보이지만 MSA 환경에서는 그렇지 않다.
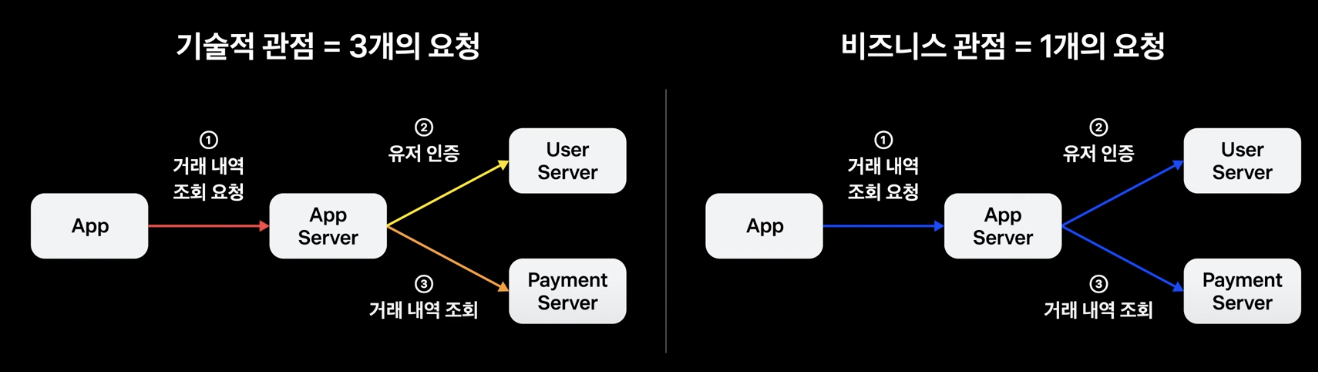
기술적 관점에서 보면 MSA 환경에서의 각 서버 간 호출이 여러 개의 개별 요청으로 해석될 수 있지만, 비즈니스 관점에서 보면 여러 개의 서버 간 호출이 하나의 요청으로 해석되는 것이 좋은 경우도 있다.
예를 들어, “User 서버 담당자가 Payment Server 담당자에게 사용자 Id 37인 고객이 몇 시쯤 거래 내역을 조회했다가 실패했다고 하는데 order Id는 모른다고 합니다. 문제의 원인을 알 수 있을까요?“ 라는 문의가 오면 답변할 수 있을까? Payment 서버 담당자는 사용자 Id를 모르기 때문에 시간 정보만 가지고 문제가 된 요청을 추적할 수밖에 없다.

만일 App, User, Payment 서버 모두가 Trace Id가 “A”라는 Trace Id를 기록해두었으면 어떨까? A라는 Trace Id로 전체 로그를 검색해 보면 Payment 서버 담당자도 사용자 Id를 알 수 있게 되므로 문제를 더 정확히 이해하고 대응하는 것이 가능하다.
이를 위해 서로 다른 서버 간 요청을 보낼 때 Trace Id 정보를 함께 보내주면 된다. 이처럼 비즈니스 관점에서 하나로 해석되면 좋을 요청에 대해 서로 다른 애플리케이션이 같은 Trace Id로 로그를 남기게 된다면 애플리케이션 간에 분산된 호출 흐름을 추적할 수 있게 되는데 이를 분산 추적이라고 한다.
이런 과정을 거쳐 서로 다른 요청이 모두 동일한 “A”라는 Trace Id를 가지게 되고 이러한 로그를 하나의 저장소로 모으는 중앙 집중식 로깅 체계를 만들고 나면, 이전에 답할 수 없었던 “사용자 Id 37인 고객이 몇 시쯤 거래 내역을 조회했다가 실패했다고 하는데 원인을 할 수 있을까요?’와 같은 문의에 답을 할 수 있게 된다.
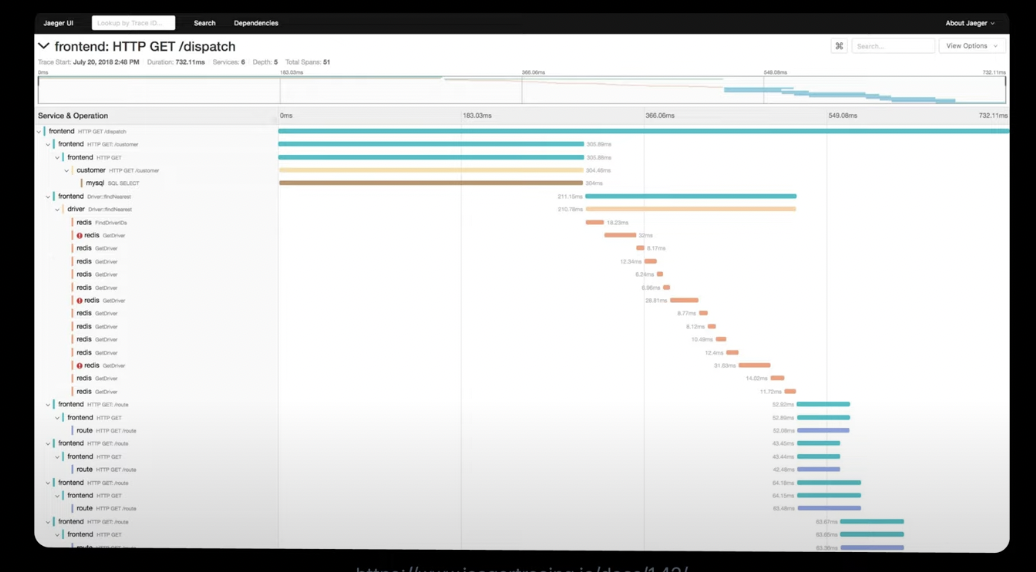
또한, 하나의 Id로 서비스 간 의존관계 및 각 서비스의 처리 시간을 알 수 있게 되므로 그림과 같이 시각화하여 요청 처리가 실패한 지점이나 성능 병목 구간을 찾는 것도 가능해진다.
토스페이먼츠는 분산 추적을 어떻게 확장하여 사용하고 있을까?
1. GlobalTrace Id 사용
토스 페이먼츠는 Trace Id보다 한 단계 더 상위에 해당하는 GlobalTrace Id를 정의해서 사용한다. 동일한 Trace Id를 서로 다른 서비스가 공유하게 된다면 비즈니스 관점에서의 하나의 요청을 처리하기 위한 전체 맥락을 이해하는 데 도움이 된다. 하지만, 우리는 비즈니스 관점에서 하나의 요청이 아닌 하나의 사용자 시나리오 전체를 이해해야 하는 상황을 자주 맞이한다.
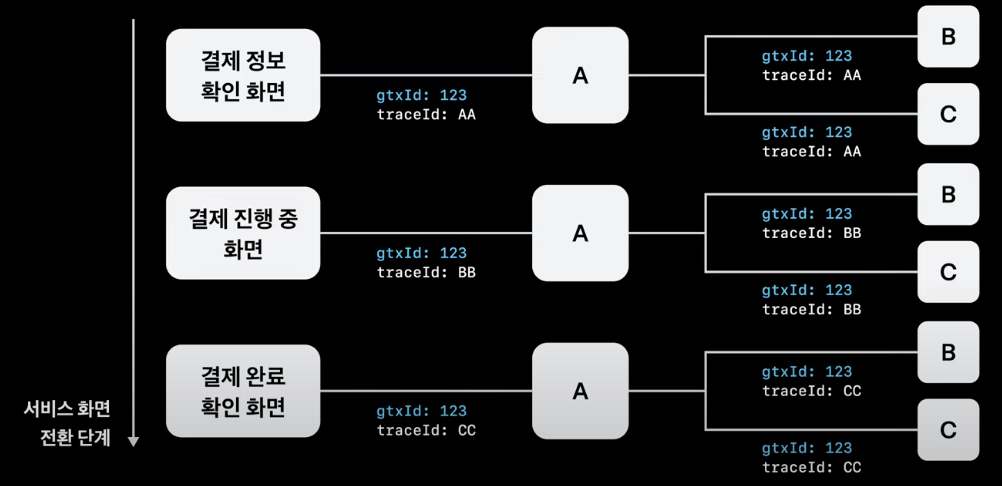
예를 들어, ‘결제 완료 확인 화면’과 관련하여 문제가 발생했는데 ‘결제 정보 확인 화면’에서부터 문제가 발생한 것으로 예상되는 경우 서비스 화면 전환 단계 전체를 엮어줄 수 있는 Trace Id가 없어 로그를 하나의 id로 검색할 수 없게 되어 빠르게 문제를 확인하는 것이 어렵다. 그래서 서비스 화면 전환 단계 전체를 엮어줄 GlobalTrace Id를 정의하고 전파하고 있다.
2. 추적 문맥 전파 항목 추가
GlobalTrace Id, Tracee Id 외에도
- API를 호출한 Client 버전
- API를 호출한 Service 명
- API를 호출한 Service 버전
- API 처리와 관련된 고객사
- API 처리와 관련된 원천사
등 추적에 도움이 되는 다양한 정보들을 함께 전파하고 있다.
그 결과 “지금 결제 실패가 자주 발생하는 것 같은데 문제가 있을까요?”라는 질문이 들어오면 “네, A 금융사와 관련된 API 처리 실패율이 다수의 서비스에서 높게 확인됩니다. 금융사에 확인 요청은 해두었고, 기술 지원팀이 고객사에 안내를 하고 있습니다”와 같이 현재 시스템 상황을 잘 이해한 상태로 답변을 할 수 있다.
3. 추적 범위 확장
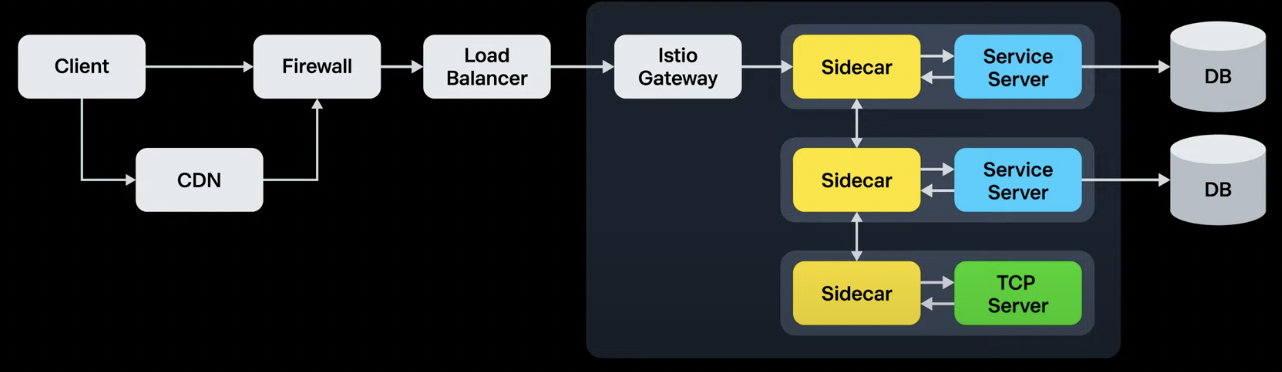
분산 추적의 범위를 MSA를 구성하는 서비스들에만 국한하지 않는다. 실제 서비스 환경은 MSA를 구성하는 서비스 이외에도 다양한 인프라 구성 요소들로 이루어져 있기 때문에 시스템에 대한 전체적인 가시성을 확보하기 위해 CDN, 방화벽, Load Balancer, Istio Gateway, Isto SideCar, DB에 이르기까지 Trace Id만 있다면 전 구간의 로그를 찾아볼 수 있도록 구성해야 한다.
DB나 TCP 서버와 같이 HTTP 헤더를 넣을 수 없는 구성 요소와의 통신은 어떻게 추적 문맥 전파를 할 수 있을까?
/* 서비스명 | globalTraceId | traceId | spanId | ... */
SELECT * FROM 테이블명 WHERE ...
DB의 경우 쿼리의 주석 부분에 추적 문맥을 포함시키면 Trace Id를 전파할 수 있다.
TCP 프로토콜 자체는 요청 본문을 변경하지 않고 추가 정보를 보낼 수 있는 방법이 없기 때문에 추적 문맥 전파가 어렵다. 하지만, L4 Load Balancer에서 TCP 요청 본문을 변경하지 않고 클라이언트 정보를 보존하여 전달하는 방법이 있다.
해결 방법을 보기 전 L7 Load Balancer를 한번 살펴보자
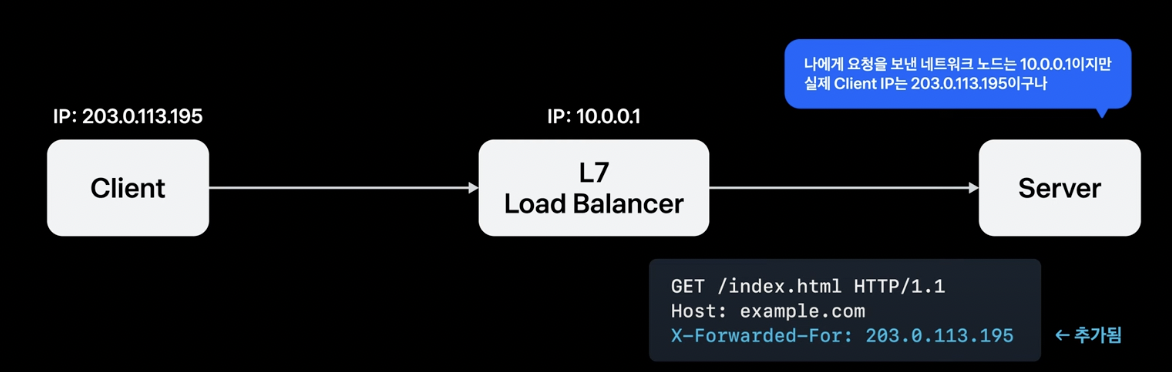
위와 같은 구조에서는 L7 Load Balancer 뒤에 있는 서버에 접속하는 클라이언트가 실제 클라이언트가 아닌 L7 Load Balancer이기 때문에 서버는 실제 클라이언트의 IP를 알 수 없는 문제가 생긴다. 이 문제를 해결하기 위해 L7 Load Balancer는 자신에게 접속한 클라이언트 IP를 X-Forwarded-For와 같은 HTTP 헤더에 담아 서버에 전달하여 서버가 실제 클라이언트 IP를 알 수 있게 해준다.
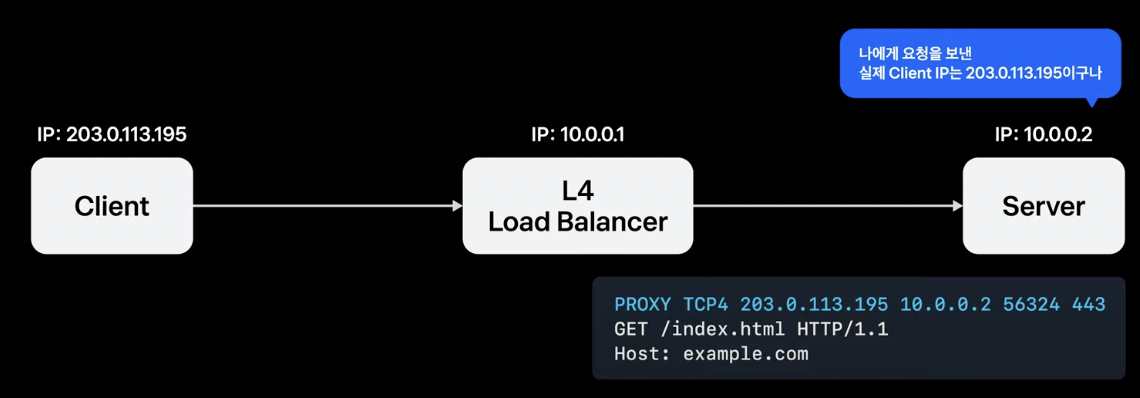
하지만, L4 Load Balancer에게 HTTP 프로토콜은 이해할 수 없는 바이트 덩어리이다. 그래서 X-Forwarded-For와 같은 추가적인 정보를 추가하지 못한다. 그래서 원래 보내고자 했던 TCP 요청 본문을 그대로 유지하고 제일 앞줄에 ‘PROXY’라는 단어와 함께 클라이언트 IP를 포함하여 전달하기로 약속한 Proxy Protocol이라는 규격을 만들어 요청 본문에 변경을 가하지 않고 추가적인 정보를 보낼 수 있다.
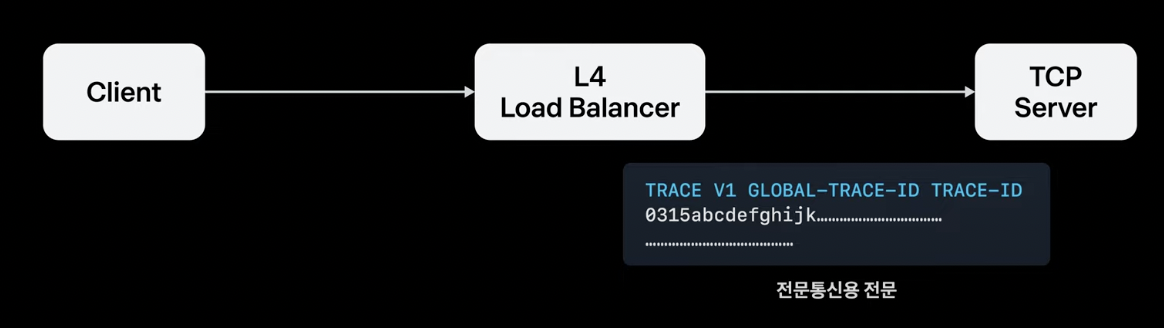
이 아이디어를 활용해 위처럼 TCP 본문의 첫 줄에 추적 문맥 정보를 심고 요청을 받는 서버가 수신되는 데이터를 규칙에 맞게 파싱 하게 하면 된다.
4. Trace Id를 클라이언트로부터 생성
프론트엔드 로직은 서버와 통신을 시작하기 전부터 로직이 실행될 수 있고 경우에 따라 서버와의 통신 이전에 사용자의 인터랙션이 발생할 수 있기 때문에 문제가 발생한 당시의 문맥을 이해하기 위해서는 문맥을 이어줄 Trace Id가 미리 발급되어 있어야 한다.
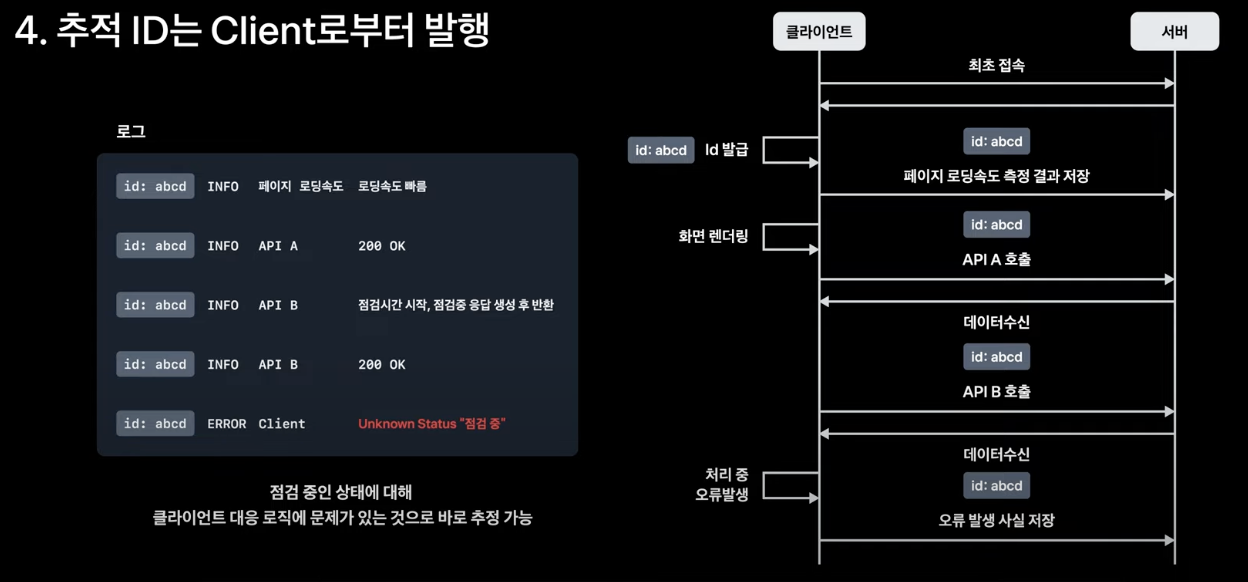
토스 페이먼츠의 프론트엔드 제품군들은 서비스 품질 및 상태 모니터링을 위해 다양한 지표를 서버로 전송한다. Trace Id를 클라이언트에서 미리 생성한 결과 사용자가 경험한 웹의 성능 지표, 크래시 발생 정보, 서버와의 통신 이력을 일관된 방식으로 확인 가능하다.
5. 분석 시스템과의 연계
토스 페이먼츠는 다양한 서비스 분석 시스템과 연계하고 있다. 에러 추적으로는 Sentry, APM(Application Perfomance Management)으로는 PinPoint를 사용하고 있다.
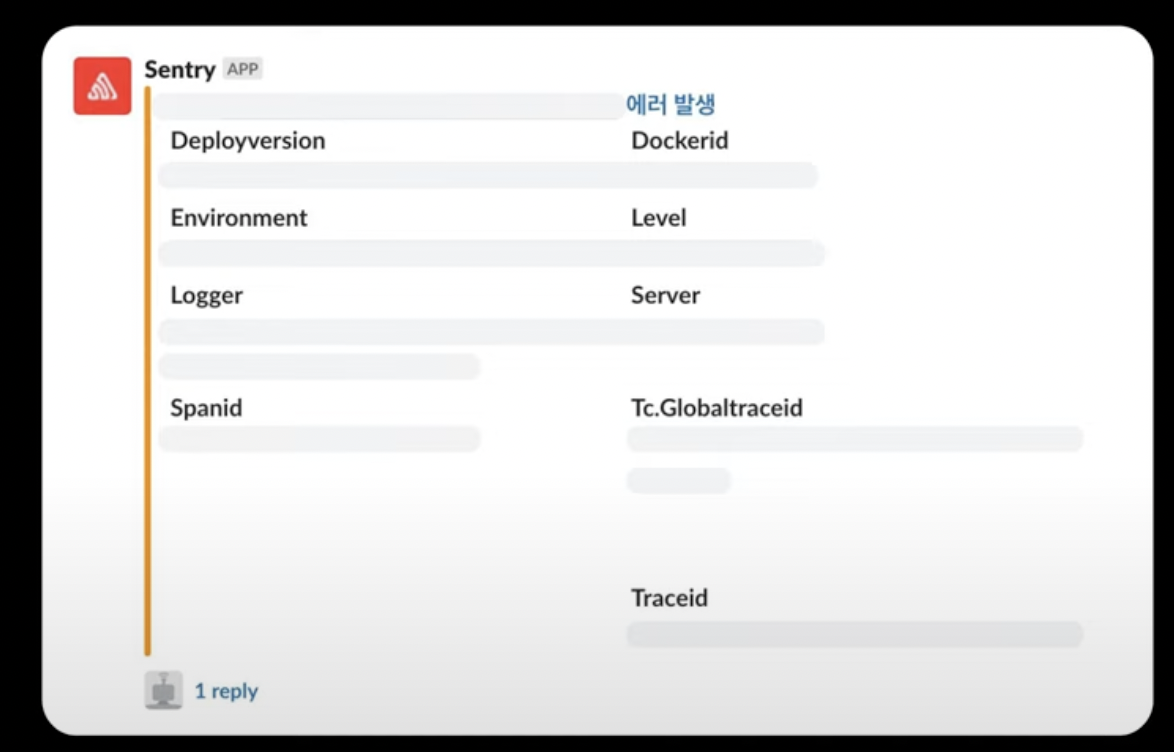
- Sentry의 경우 tag라는 기능을 통해 GlobalTrace Id, Trace Id 등을 넣어 검색이 가능하다.
- Pinpoint의 경우 Pinpoint Transaction Id를 MDC(Mapped Diagnostic Context)에 pTx Id라는 키로 노출하며 Pinpoint에서 성능 문제를 검색할 수 있도록 하고 있다.
FIN.
현재 토스와 같은 Observability 시스템을 구축하기 위해서는 하나의팀, 분야뿐 아니라 회사 전체적으로 협력이 있었어야 될 것 같은데 얼마나 토스가 잘 협력하고 관리되고 있는지 알 수 있는 컨퍼런스 영상인 것 같다.
프로젝트에서 간단하게 모니터링 시스템을 구축해 보면서 만약 로그가 복잡하게 되면 어떤 게 추가될 수 있고 여러 개의 분산 서버에서는 로그를 어떻게 관리할 수 있는지에 대해 궁금한 점이 많았었는데 많이 해결되었다 🙇🏻♂️
요즘 새로운 프로젝트를 하고 있는데 해당 프로젝트는 장기간 유지 보수 및 운영해 보며 다양한 문제 상황을 경험하고 해결해 보고 싶다. 그 과정에서 오늘 포스트한 내용도 적용해 볼 수 있지 않을까.
참고:
*오타가 있거나 피드백 주실 부분이 있으면 편하게 말씀해 주세요.