우테코 - 웹 자동차 경주 회고
웹 자동차 경주 미션을 회고해보자~

이번 웹 자동차 경주 미션은 Level 1 때 했던 콘솔 자동차 경주에 Spring과 DB를 적용해 웹 자동차 경주로 변환하는 미션이다.
처음 콘솔에서 웹으로 전환해 보는 과정이라 신기하면서도 재밌었다. 하지만 그 과정 속에서 헷갈리거나 혼란스러운 부분이 많았다. dao와 repository, entity의 정의? 등 헷갈리는 부분이 많아서 많은 고민을 해보며 성장했던 것 같다.
그리고 웹으로 전환하면서 Spring과 DB를 도입했는데 뭔가 레벨 1 때의 객체지향을 잊어버리고 데이터 중심적으로 짠 거 같아 아쉬움이 많이 남아 앞으로 이를 잘 생각해 보며 짜야겠다는 생각이 들었다.
데이터 중심 관점 설계
이번에 api의 결과 값으로 다음과 같은 Response를 응답해줘야 됐다.
HTTP/1.1 200
Content-Type: application/json
[
{
"winners": "브리",
"racingCars": [
{
"name": "브리",
"position": 6
},
{
"name": "토미",
"position": 4
},
{
"name": "브라운",
"position": 3
},
]
},
{
"winners": "브리,토미,브라운",
"racingCars": [
{
"name": "브리",
"position": 6
},
{
"name": "토미",
"position": 6
},
{
"name": "브라운",
"position": 6
},
]
}
]
그래서 처음에 다음과 같은 table을 만들게 되었는데.. 지금보니 참 무지성으로 만든거 같다 ㅋㅋㅋ
CREATE TABLE PLAY_RESULT (
id BIGINT NOT NULL AUTO_INCREMENT,
winners VARCHAR(50) NOT NULL,
trial_count INT NOT NULL,
created_at DATETIME NOT NULL default current_timestamp,
PRIMARY KEY (id)
);
CREATE TABLE PLAYER (
id BIGINT NOT NULL AUTO_INCREMENT,
play_result_id INT NOT NULL,
name VARCHAR(5) NOT NULL,
position INT NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY (play_result_id) REFERENCES PLAY_RESULT (id)
);
위처럼 설계하여 제출하였더니, 리뷰어님께서 다음과 같이 피드백을 주셨다.
이번에는 PlayerResult를 제거하고, 도메인 내에서 raw한 DB값을 통해 결과값을 계산해보게 도메인을 구성해보셨으면 좋겠어서, 한번더 요청드립니다 :)
생각해 보면 PlayerResult는 결과물인 데이터에 초점이 맞춰져 있어 데이터베이스가 view에 의존적이고 재사용하지 못해 유연성이 떨어진다. 그리고 PLAYER 만으로 충분히 만들 수 있기 때문에 불필요한 테이블이라고 생각해 볼 수 있었다.
그래서 이번엔 PLAY_RESULT에 사용하지 않는 필드는 지워 각 게임에 대한 식별자인 id만 주고 PLAYER에서 승자를 판단할 수 있게 winner 필드를 하나 추가해 주었다. 지금 생각해 보니 PLAY_RESULT 테이블을 지우지 않은 건, 각 게임에 대한 플레이어들을 PLAY_RESULT_ID로 쉽게 찾기 위해 남겨뒀지 않나 생각이 든다.
CREATE TABLE PLAY_RESULT (
id BIGINT NOT NULL AUTO_INCREMENT,
PRIMARY KEY (id)
);
CREATE TABLE PLAYER (
id BIGINT NOT NULL AUTO_INCREMENT,
play_result_id BIGINT NOT NULL,
winner BOOL NOT NULL,
name VARCHAR(5) NOT NULL,
position INT NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY (play_result_id) REFERENCES PLAY_RESULT (id)
);
역시 무지몽매한 나는 리뷰어님의 의도를 한 번에 이해하지 못해서 또 한 번 피드백으로 뚜드려 맞았다.
PlayResult는 어떤 역할을 하는걸까요? 단순 데이터 저장의 역할을 하는것으로 보이는데요.
이경우, 해당 테이블은 객체지향의 관점에서 나온걸까요, 아니면 데이터 중심의 관점에서 나온걸까요?
객체들의 협력이 이루어지는 애플리케이션을 작성하기 위해서는, 각 객체들의 역할과 책임, 그리고 각 객체들의 협력을 집중하는 것이 우선시 되야한다 생각하는데요.
현재 PlayResult의 경우, 하나의 자료구조로 밖에 보이지 않아요.
그 이유로는
- 속성이 auto-increse되는 id뿐이다.
해당 속성은 자바 객체의 기본 식별자인 주솟값과 별반 차이가 없어 보여요. 식별의 책임을 DB에서 수행하게 위임한거라 판단됩니다. 즉 이경우 result의 식별자를 저장하기 위한 하나의 bundle로 보이며, 이는 PLAYER 테이블의 속성으로 가져가도 좋아보여요. (테이블의 이름도 GAME등으로 변경되도 문제없어보여요)
만약 조금더 객체지향의 관점에서 시작했다면 어땠을까요?!
- Result 보단은 각각의 PLayer가 책임을 수행하기 위해 필요한 속성이 무엇인지 고려한다.
- Player의 결과를 Player가 알고있는가?
- 혹은 알고있어야 하는가?
- 결과를 책임져줄 친구는 없을까?
- 여기서는 어떤 객체가 필요할까?
등이 되지 않았을까 생각합니다 :)
각 게임에 대한 플레이어들을 PLAY_RESULT 테이블 없이도 충분히 가능하고, PLAYER에 winner 필드가 없이도 충분히 구현 단계에서 객체지향적으로 구현 가능하다.
CREATE TABLE PLAYER (
id BIGINT NOT NULL AUTO_INCREMENT,
game BIGINT NOT NULL,
name VARCHAR(5) NOT NULL,
position INT NOT NULL,
PRIMARY KEY (id)
);
위와 같이 테이블을 설계 후 구현 단계에서 결과를 책임져줄 객체를 생성해 주어 game마다 player들의 position을 비교해서 승자를 판별하여 winners와 players들을 만들어 응답해 주면 된다.
LEVEL2가 되면서 Spring과 DB를 도입을 해 공부에 대한 우선순위가 이쪽으로 많이 기울어졌다. 그래서 점점 LEVEL1 때 공부한 객체지향을 조금씩 놓치고 있던 것 같다. 하지만 결국 스프링은 결국 개발자가 더 객체지향적으로 짤 수 있게 도와주는 프레임워크이다. 본질인 객체지향을 놓치지 말고 함께 균형을 맞춰가며 LEVEL2 미션을 진행해나가야겠다.
+) 이미 미션이 Merge 되어서 더 pr을 보낼 수 없었지만 리뷰어님의 의도가 내가 결론 내린 부분과 맞는지 궁금했기 때문에 개인적으로 DM을 남겼다! 주말인데도 성심껏 답변해 주시는 리뷰어님.. 감사합니다 🙇🙇🙇 예시를 들으니 더욱더 와닿는 거 같다.

DAO vs Repository
둘 다 데이터베이스나 영속성 접근을 캡슐화하는 역할을 수행하는 데 구체적으로 둘이 어떤 게 다르고 어떻게 사용할 수 있을까?
DAO(Data Access Object)
DAO는 데이터에 접근하기 위한 객체로 데이터베이스 혹은 다른 영속성(Persistence)에 대한 접근을 추상화해주는 역할을 수행한다. 쉽게 말하면 응용 계층에서 어떤 영속성 저장 방식을 사용할 것인지 알 필요 없게 하는 역할을 한다고 생각하면 된다.
public class CarService {
private final PlayerDao playerDao;
...
}
public interface PlayerDao {
void insertAll(List<Player> players);
List<Player> findAllPlayer(long playResultId);
}
//InMemory를 이용하여 Player를 저장하는 dao
public class PlayerInMemoryDao implements PlayerDao {
...
}
//JDBC를 이용하여 Player를 저장하는 dao
@Repository
public class PlayerJdbcDao implements PlayerDao {
...
}
Repository
Repository는 도메인 영역에서 도메인을 다루기 위한 저장소의 역할로 추상화되어 있다. 예를 들어, 하나의 주문을 저장할 때 주문뿐 아니라 주문 상품들도 같이 저장되어야 하고 조회, 삭제시에도 같이 조회, 삭제되어야 한다고 하자.
@Service
@Transactional
public class OrderService {
private final OrderDao orderDao;
private final OrderItemDao orderItemDao;
public OrderService(final OrderDao orderDao, final OrderItemDao orderItemDao) {
this.orderDao = orderDao;
this.orderItemDao = orderItemDao;
}
//주문 저장 시 주문 상품들도 같이 저장
public void order() {
orderDao.save();
orderItemDao.save();
}
//주문 조회 시 주문 상품들도 같이 조회
public Order findOrder() {
Order order = orderDao.find();
List<OrderItem> orderItems = orderItemDao.findAllByOrder();
order.setOrderItems(orderItems);
return order;
}
// 주문 삭제 시 연관된 주문들 또한 같이 삭제
public void deleteOrder() {
orderItemDao.delete();
orderDao.delete();
}
}
여기서 주문과 함께 저장, 조회, 삭제되어야 될 것들이 늘어나면 Service 코드도 계속해서 변경되어야 한다. 이는 Domain Model에 대한 캡슐화가 잘되지 않았기 때문에 발생한 일이다. 주문을 저장, 조회, 삭제할 때 주문 항목들도 같이 저장, 조회, 삭제되게 하는 주문이라는 도메인 엔티티의 진입점 역할을 하는 OrderRepository를 사용하면 OrderService의 복잡도를 줄일 수 있다.
@Service
@Transactional
public class OrderService {
private final OrderRepository orderRepository;
public PlaceOrderService(final OrderRepository orderRepository) {
this.orderRepository = orderRepository;
}
public void order() {
orderRepository.save(order); //Order와 OrderItem을 함께 저장
}
public Order findOrder() {
return orderRepository.findById(); // OrderItem이 세팅된 Order조회
}
public void deleteOrder() {
orderRepository.deleteById(); //Order와 관련된 OrderItem을 함께 삭제
}
}
즉, Repository는 연관이 있고 함께 동작이 수행해야 되는 여러 도메인 모델 사이에서 진입점을 제공해 해당 도메인을 다루는 저장소의 역할이라 할 수 있다. 하지만 이번 웹 자동차 경주에서는 이렇게 연관된 도메인을 다룰 일이 없어서 repository는 따로 생성하지 않고 dao만 구현해서 진행하였다!
DTO와 Domain 간의 변환 작업은 어디서 수행?
우선 Repository Layer는 영속성을 관리하는 계층으로 Client에서 사용할 DTO를 Repository에서 변환하는 건 맞지 않다고 생각했다.
그럼 Controller는 어떨까? Controller에서 생성하게 되면 다음과 같은 단점이 있을 것 같다.
- Domain이 Controller에 결합됨
- 각 Domain을 가져오기 위한 service의 수가 많아질 수 있음
- 각 Domain들을 가져와서 가공할 일이 있을 경우 비즈니스 로직이 Controller에 들어갈 수 있음
그래서 결국 Service에서 DTO로 변환하는 역할을 주었는데 그렇다고 Service에 있는 게 완벽하냐고 하면 또 그렇지 않다.
- Service 단계에서 각 상황에 맞는 dto를 알고 있어야 되니 presentation 영역을 침범(즉, view에 의존)
- Service 레이어에 DTO가 들어오지 않아야, 여러 종류의 컨트롤러에서 해당 서비스 사용 가능
결국 또 진리의 trade off이다.. 상황에 맞게 써야 하는데 그 상황은 많이 겪어보지 않았으니 앞으로 미션들에 이것저것 적용해 보면서 겪어봐야 될 것 같다.
DB Entity vs Domain Entity?
예전에 JPA를 이용해서 프로젝트를 할 때 하나의 Entity 객체가 DB관점에서의 Entity 역할도 수행하고 Domain 관점으로의 Entity도 수행했기 때문에 이번에 다음과 같이 두 개의 객체로 나눠져서 진행하니 약간 혼란스러웠다.
//JPA
@Entity
public class Car {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private final Name name;
private final Position position;
...
}
//이번 미션
public class Car {
private final Name name;
private final Position position;
...
}
public class CarEntity {
private long id;
private final String name;
private final int position;
...
}
그래서 리뷰어님께 질문드렸었는데 질문할 당시에는 용어가 헷갈렸어서 Entity vs Domain Model로 질문을 해버렸다.. 하지만 덕분에 각 용어에 대해 자세히 알게 되어서 오히려 좋아 👍👍
도메인
- 해결하고자 하는 문제 영역
도메인 모델(Domain Model)
- 도메인(문제 영역)을 개념적으로 표현한 것
- UML, Diagram, graph, formula 등등
- 개념 영역
도메인 모델 패턴(Domain Model Pattern)
- 도메인(문제 영역)을 객체 지향 기법으로 구현하는 패턴
- 도메인 계층의 객체 모덺
- 구현 영역
엔티티(Entity)
- 도메인 모델을 구현하기 위한 도구
- 구현 영역
무민이 docs에 적어주신 요구사항은 도메인을 모델링하기 위한 첫 발걸음이에요.
즉 요구사항에서는, 핵심 구성요소, 규칙, 기능들이 포함되어 있는데, 이것 자체가 도메인 모델이죠.
요구사항을 개념적으로 도출했으니, 이를 구현해야겠죠?
이는 객체지향으로도, 절차지향으로도, 함수형으로도 작성될 수 있어요.
저희는 java를 쓰고 있으니, 자연스럽게 도메인 모델 패턴을 사용하여, 도메인 모델 패턴을 사용하여, 객체 모델로 구현을 할 거고, 이때 필요한 객체들이 entity나 값 객체가 되는것들이에요.
https://martinfowler.com/bliki/EvansClassification.html
위의 마틴 파울러의 글에서 마지막 문단을 읽어보면 이 용어(Entity)는 다른 개념과 심하게 뒤섞인다. 엔티티는 종종 데이터베이스 테이블 또는 데이터 베이스 테이블에 해당하는 객체를 나타내는데 사용되기 때문에 이 용어를 사용하는 경우 어떤 의미에 따라 사용하고 있는지 명확히 해야 된다고 한다.
즉, Entity의 이러한 혼란은 어떠한 맥락에 따라 말하는지 달라지기 때문에 당연한 것이다.
API Error 처리
콘솔에서 하던 것처럼 에러를 throw 하면 스프링 부트가 기본 오류 처리로 500 Internal Server Error를 던져준다. 그래서 에러마다 다른 메시지, 상태 코드(400)를 던져주기 위해 @ExceptionHandler, @ControllerAdvice를 적용해 보고 어떤 원리로 작동하는지 궁금해서 정리해 봤다.
개행 관련 설정
마지막 줄 개행 누락
한번 씩 파일마다 마지막 줄에 개행이 누락된 것이 자꾸 보인다..ㅠ 방지하기 위해 Intellij 설정을 해보자
Preferences(설정) -> Editor(에디터) -> General(일반)에서 제일 아래 On Save(저장 시) 부분에서 Ensure every saved file ends with a line break(모든 저장된 파일이 줄 바꿈으로 끝나도록 함) 부분을 체크하면 된다.
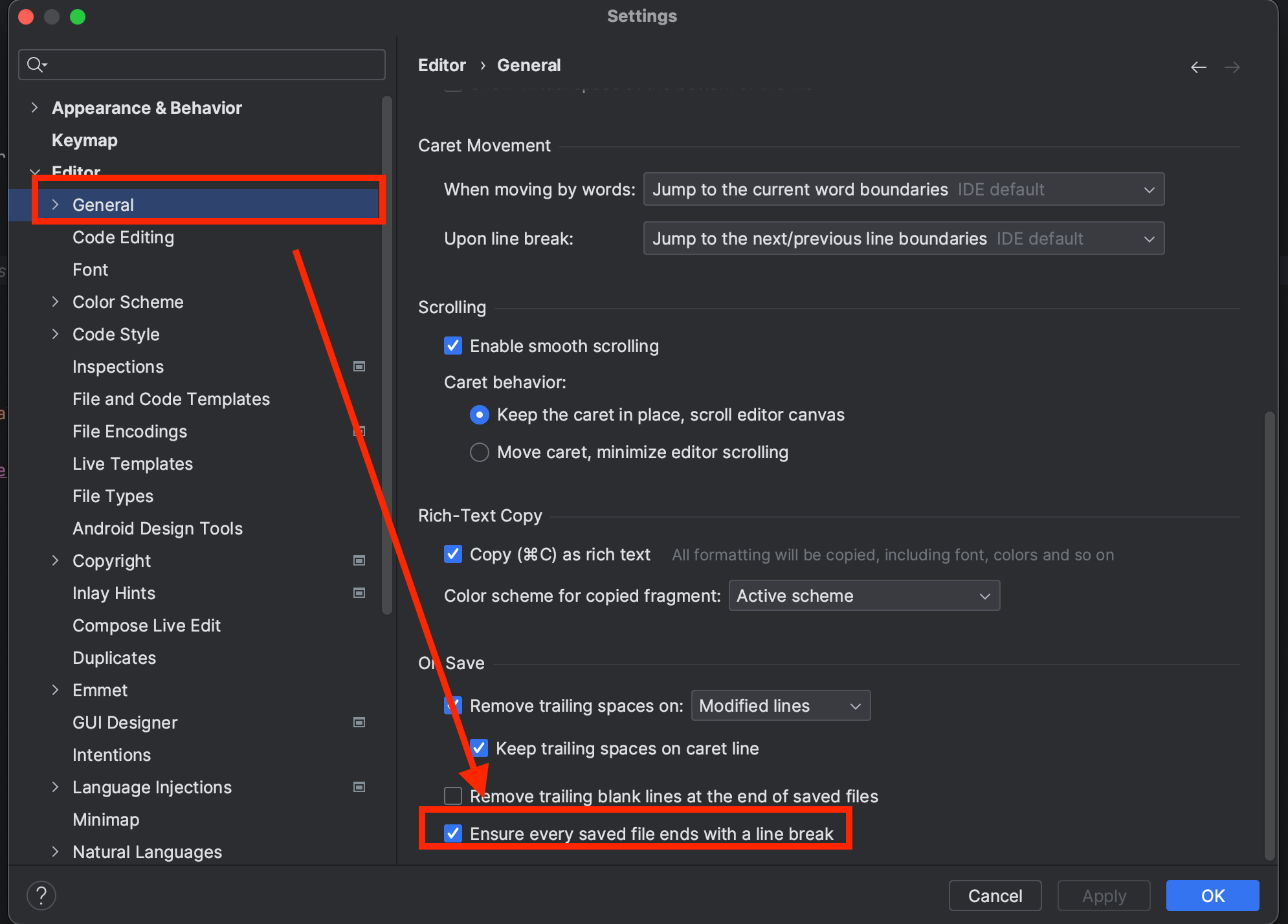
코드 스타일 설정
Preferences(설정) -> Editor(에디터) -> Code Style(코드 스타일)에서 Schema(구성표)를 원하는 포맷 스타일로 설정해서 Command + Option + I로 전체 코드를 통일성 있게 가져갈 수 있다.
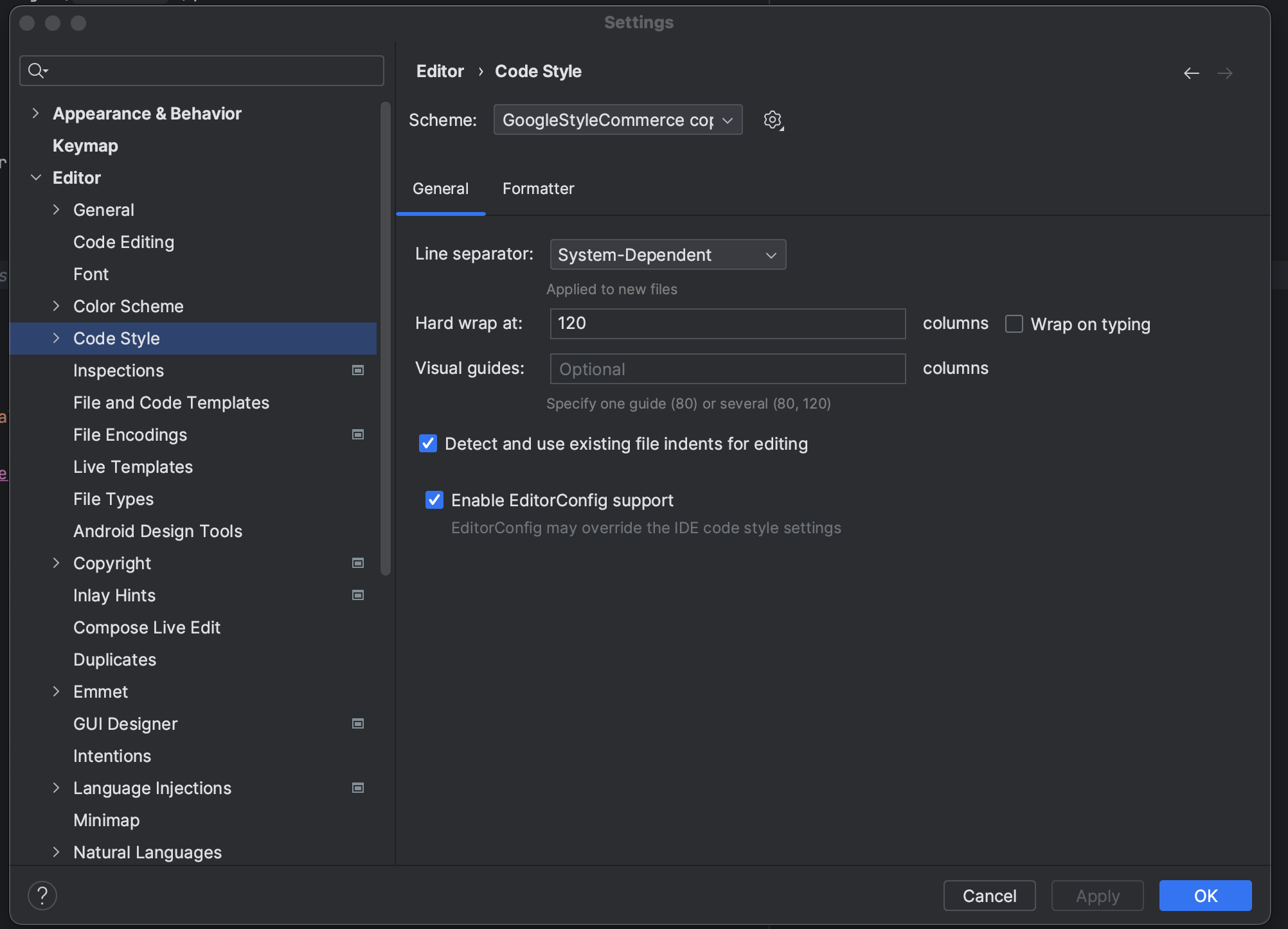
많은 사람들이 쓰는 Google Style을 적용해보자
- https://github.com/google/styleguide에서 intellij-java-google-style.xml을 다운로드 후
- Schema(구성표) 옆에 있는 톱니바퀴를 누른 후 Import Sheme(구성표 가져오기) -> Intellij IDEA code style XML를 선택하고 다운받은 xml 선택
+리뷰어님께 받은 코드 리뷰에 대해 관심이 있으면 다음 PR들을 참고!
참고:
*틀린 부분이 있으면 언제든지 말씀해 주시면 공부해서 수정하겠습니다.