도메인 완전성과 순수성(+도메인 모델과 영속 모델 분리)
Domain integrity and purity
우선 도메인의 완전성과 순수성에 대해 얘기하기 전에 빈약한 도메인 모델과 풍부한 도메인 모델에 대해 살펴보자.
빈약한, 풍부한 도메인 모델
public class User {
private Long id;
private String name;
private List<Item> items;
}
public class Item {
private Long id;
private String name;
private int price;
}
public class UserService {
...
public int calculateTotalPrice(long id) {
User user = userRepository.findById(id);
List<Item> items = user.getItems();
int sum = 0;
for (Item item : items) {
sum += item.getPrice();
}
return sum;
}
...
}
빈약한 도메인 모델은 상태를 표현하는 필드와 getter, setter 메서드만 존재하고 비즈니스 로직이 서비스 계층에 존재하게 된다. 위와 같은 같은 객체를 제대로 된 객체라고 할 수 있을까? 객체지향적인 개발이라 하면 객체들이 속성을 가지고 있음을 넘어서 서로 상호작용하며 메시지를 주고받을 수 있어야 된다. 해당 도메인 객체에 대한 비즈니스 로직이 있으면 서비스 레이어가 아닌 해당 도메인에 작성되고 서비스 레이어에서는 여러 객체가 조합되거나 외부 의존성과 연동되는 로직이 작성된다. 이렇게 함으로써 좀 더 객체지향적인 개발과 도메인 응집도를 높일 수 있다.
public class User {
private Long id;
private String name;
private List<Item> items;
public int calculateTotalPrice() {
int sum = 0;
for (Item item : items) {
sum += item.getPrice();
}
return sum;
}
}
public class Item {
private Long id;
private String name;
private int price;
}
도메인 모델 완전성 vs 도메인 모델 순수성
public class User {
...
public Result ChangeEmail(string newEmail, UserRepository repository)
{
if (Company.IsEmailCorporate(newEmail) == false)
return Result.Failure("Incorrect email domain");
User existingUser = repository.GetByEmail(newEmail);
if (existingUser != null && existingUser != this)
return Result.Failure("Email is already taken");
Email = newEmail;
return Result.Success();
}
...
}
public class UserController {
...
public string ChangeEmail(int userId, string newEmail)
{
User user = _userRepository.GetById(userId);
Result result = user.ChangeEmail(newEmail, _userRepository);
if (result.IsFailure)
return result.Error;
_userRepository.Save(user);
return "OK";
}
...
}
완전한 도메인 모델은 모든 비즈니스 논리가 도메인 클래스에 위치한다. (외부 의존성과 상호작용 논리조차도) 즉, 도메인 논리 단편화가 존재하지 않아 도메인 논리가 도메인 계층 이외에는 존재하지 않는다.
하지만, 이 경우 도메인 모델 순수성을 희생한다. 순수성이라는 것은 도메인 클래스는 원시 유형 또는 다른 도메인 클래스에만 의존해야 한다는 것이다. 위 코드를 순수성을 유지하도록 변경하면 다음과 같이 변경할 수 있을 것이다.
public class UserController {
...
public string ChangeEmail(int userId, string newEmail)
{
/* validation */
User existingUser = _userRepository.GetByEmail(newEmail);
if (existingUser != null && existingUser.Id != userId)
return "Email is already taken";
User user = _userRepository.GetById(userId);
Result result = user.ChangeEmail(newEmail);
if (result.IsFailure)
return result.Error;
_userRepository.Save(user);
return "OK";
}
...
}
그러나 이 경우는 도메인 논리 단편화가 발생한다. 도메인 계층에 모든 비즈니스 로직이 존재하지 않는다는 것이다. 이처럼 완성도와 순수성 두 가지를 동시에 가질 수 없다.
하지만, 위 두 가지를 가질 수 있는 방법이 있다. 바로 성능을 포기하는 것이다.
public class User {
...
public Result ChangeEmail(string newEmail, User[] allUsers)
{
if (Company.IsEmailCorporate(newEmail) == false)
return Result.Failure("Incorrect email domain");
bool emailIsTaken = allUsers.Any(x => x.Email == newEmail && x != this);
if (emailIsTaken)
return Result.Failure("Email is already taken");
Email = newEmail;
return Result.Success();
}
...
}
public class UserController {
...
public string ChangeEmail(int userId, string newEmail)
{
User[] allUsers = _userRepository.GetAll();
User user = allUsers.Single(x => x.Id == userId);
Result result = user.ChangeEmail(newEmail, allUsers);
if (result.IsFailure)
return result.Error;
_userRepository.Save(user);
return "OK";
}
...
}
파라미터에 모든 User를 넣어줘 순수성을 보장해 주었다. 위 코드는 순수성과 완전성을 둘 다 가진다고 할 수 있지만 성능 관점에서는 실용적이라 할 수 없다.
결국 완전성, 순수성, 성능 세 마리 토끼를 모두 잡을 수는 없고 어느 하나를 포기하는 선택을 해야 한다.
- 완전성, 순수성(성능 희생)
- 완존성, 성능(순수성 희생)
- 성능, 순수성(완전성 희생)
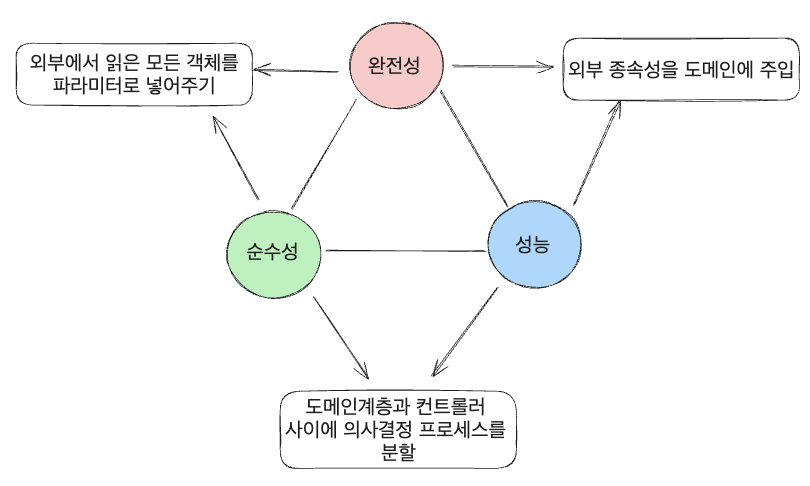
성능을 희생하고 완전성, 순수성을 보장해 주기 위해서는 외부에서 읽은 모든 객체를 파라미터로 넣어주면 된다. 하지만, 이 방법 같은 경우 비교하려는 모든 데이터를 애플리케이션에 로딩한다는 건데 실용성이 너무 없다.
그렇기 때문에 순수성을 희생하는 두 번째 옵션과 완전성을 희생하는 세 번째 옵션 중 택할 수 있다. 외부 종속성을 도메인에 주입하여 순수성을 희생시키는 비용과 도메인 계층과 컨트롤러 사이에 의사결정 프로세스를 분할하여 완전성을 희생시키는 비용을 생각해 보면 순수성보다는 완전성을 희생하는 것이 좋다. 논리 단편화로 응집도가 조금 떨어지는 것보다 도메인에 외부 종속성이 추가되는 것이 복잡성이 훨씬 커지기 때문이다. 도메인에 외부 종속성이 있을 때 단위 테스트는 과연 어떻게 해야 될까 생각해 보자.
도메인 모델과 영속 모델 분리
도메인 순수성이 중요하다는 건 알겠다. 근데 이런 생각이 들었다. JPA를 사용하게 되면 일반적으로 JPA Entity을 통합적으로 사용하게 되는데 이 경우 도메인이 순수하다고 할 수 있을까? (결국 JPA를 사용 안 하게 되면 달았던 애노테이션 부분을 다 지워야 될 테니깐)
그래서 JPA를 사용하면서 순수성을 보장하려면 도메인 모델과 영속 모델이 분리되어야 될 것 같은데 이게 이전에 읽었었던 만들면서 배우는 클린 아키텍쳐의 맥락과 일맥상통할 것 같다. (예제 코드 참고)
하지만, 이렇게 사용하게 될 경우 도메인, 영속 모델을 같이 관리해야 하는 오버헤드도 크고 연관관계가 복잡한 경우 영속화하는 과정도 복잡하다. 그렇기 때문에 트레이드오프를 잘 고려하고 사용하자.
개인적으로는 해당 방법으로 한번 프로젝트를 진행해 보고 싶긴 한데 잘 엄두가 안 난다. 나중에 영속 매커니즘이 유연해야 하는 시스템에서 사용해 볼 수 있을 것 같은데 그게 언제지…? 앞으로 계속 고민해 볼 숙제가 생겼다. 개발이란 그런 것 같다. 새로운 것을 공부할 때 이전 기억과 퍼즐이 맞춰져서 매우 짜릿한 동시에 또 새로운 숙제거리가 주어진다 ㅋㅋㅋ 그래도 이게 개발의 매력이 아닐까
참고:
*틀린 부분이 있으면 언제든지 말씀해 주시면 공부해서 수정하겠습니다.