우당탕탕 쿼리 성능 개선하기
Improve to more elegant maintainable test code
현재 우리 api 중 가장 많이 호출되는 메인 api는 반려동물 식품 조회이다. 데이터가 적을 때는 상관없었지만 100만 데이터 이상 일때 심각한 성능 이슈를 보이는 걸 확인하였다. 무려 한번 조회할 때마다 10초(아무 필터가 없을 때는 1분 이상도 걸림) 정도 걸리고 있는데

이 정도면 절대 서비스를 할 수 없는 수준이다. 왜 이렇게 오래 걸리는 걸까?
페치 조인과 페이지네이션
select
distinct p1_0.id,
p1_0.brand_id,
b1_0.id,
b1_0.created_at,
b1_0.founded_year,
b1_0.has_research_center,
b1_0.has_resident_vet,
b1_0.image_url,
b1_0.modified_at,
b1_0.name,
b1_0.nation,
p1_0.created_at,
p1_0.eu_standard,
p1_0.us_standard,
p1_0.image_url,
p1_0.modified_at,
p1_0.name,
p2_0.pet_food_id,
p2_0.id,
p2_0.primary_ingredient_id,
p1_0.purchase_link
from
pet_food p1_0
join
brand b1_0
on b1_0.id=p1_0.brand_id
join
pet_food_primary_ingredient p2_0
on p1_0.id=p2_0.pet_food_id
join
pet_food_functionality p3_0
on p1_0.id=p3_0.pet_food_id
where
b1_0.name in (?,?)
and p1_0.us_standard=?
and exists(select
1
from
pet_food_primary_ingredient p5_0
join
primary_ingredient p6_0
on p6_0.id=p5_0.primary_ingredient_id
where
p6_0.name in (?,?)
and p1_0.id=p5_0.pet_food_id)
and exists(select
1
from
pet_food_functionality p7_0
join
functionality f1_0
on f1_0.id=p7_0.functionality_id
where
f1_0.name in (?,?)
and p1_0.id=p7_0.pet_food_id)
쿼리를 확인해 봤는데 분명 페이징 20을 걸었는데 limit이 안 날아가고 있는 걸 확인했다. 즉, 모든 데이터를 애플리케이션단으로 읽어들이고 있다는 얘기였다. 하지만, 클라이언트에서 받은 데이터를 확인해 보면 20개만 잘 날라오고 있다. 해당 쿼리 위에 다음과 경고 로그가 떠있다.
WARN org.hibernate.orm.query - HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
컬렉션 가져오기로 지정된 첫 번째 결과/최대 결과가 메모리에서 적용되고 있다는 경고였다. 이 로그를 보자마자 예전에 공부했었던 페치조인과 페이징을 동시에 사용하면 생기는 문제점이 떠올랐고 바로 우리 코드를 살펴봤다.
queryFactory
.selectDistinct(petFood)
.from(petFood)
.join(petFood.brand, brand)
.fetchJoin()
.join(petFood.petFoodPrimaryIngredients, petFoodPrimaryIngredient)
.fetchJoin()
.join(petFood.petFoodFunctionalities, petFoodFunctionality)
.where(
isLessThan(lastPetFoodId),
isContainBrand(brandsName),
isMeetStandardCondition(standards),
isContainPrimaryIngredients(primaryIngredientList),
isContainFunctionalities(functionalityList)
)
.orderBy(petFood.id.desc())
.limit(size)
.fetch();
현재 우리는 QueryDsl을 사용 중이다. fetchJoin과 limit이 같이 사용되고 있어서 저런 경고 로그가 찍히고 있다. fetch() 메서드를 한번 들어가 보자
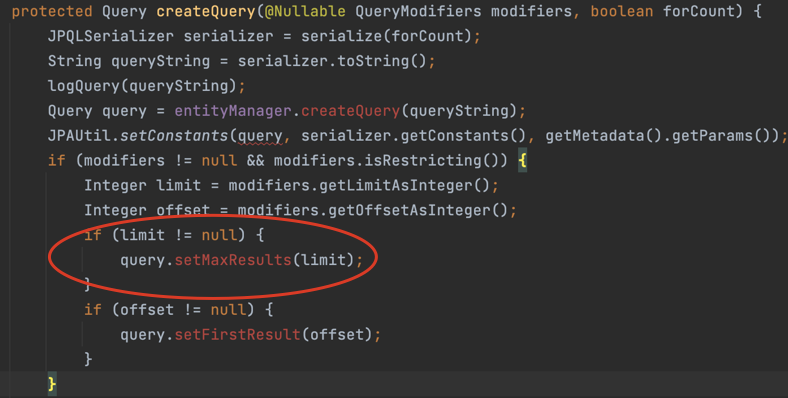
limit으로 maxResult를 채워주고 있다.(offset -> firstResult)
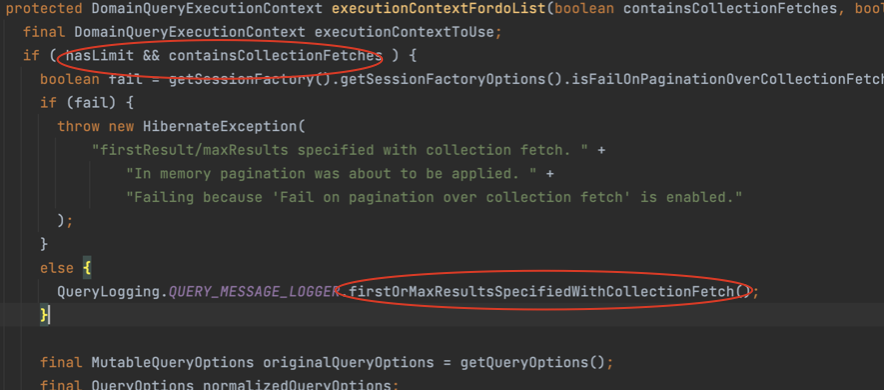

그리고 limit과 collectionFetchf를 포함하고 있으면 QueryLogging.QUERY_MESSAGE_LOGGER.firstOrMaxResultsSpecifiedWithCollectionFetch()가 실행되어 해당 로그가 찍히게 된다.
결국에는 해당 경고 로그를 찍어주고 애플리케이션으로 모든 데이터를 가져와서 페이징 처리를 한다는 것인데 왜 경고를 찍어주는 것일까? 우선 일대다 같은 경우 페치 조인을 하면 데이터가 뻥튀기가 되어서 데이터 수가 변하기 때문에 페이징을 할 수가 없다. 그래서, 모든 데이터를 애플리케이션 단에 다 가져와서 페이징 처리를 하게 된다. 이때 100만 개 이상의 데이터가 있다고 하면 성능 이슈가 발생할 뿐만 아니라 Out of Memory가 발생할 수도 있다.
또한, 잘 생각해 보면 페치조인으로 가져오는 N 관계의 테이블을 사용하지도 않고 where 절에서 조건으로만 사용한다. 그렇기 때문에 해당 join(join, fetchJoin)들을 삭제해 주었고 hibernate 6.0부터 distinct를 자동으로 적용해 주고 있기 때문에 distinct도 제거했다. 만약 여기서 지연 로딩한 부분을 나중에 사용하게 된다고 하면 N+1이 터질 것이다. 그런 경우는 BatchSize를 조절해서 최적화해주면 된다.
queryFactory
.select(petFood)
.from(petFood)
.join(petFood.brand, brand)
.fetchJoin()
.where(
isLessThan(lastPetFoodId),
isContainBrand(brandsName),
isMeetStandardCondition(standards),
isContainPrimaryIngredients(primaryIngredientList),
isContainFunctionalities(functionalityList)
)
.orderBy(petFood.id.desc())
.limit(size)
.fetch();
select
p1_0.id,
p1_0.brand_id,
b1_0.id,
b1_0.created_at,
b1_0.founded_year,
b1_0.has_research_center,
b1_0.has_resident_vet,
b1_0.image_url,
b1_0.modified_at,
b1_0.name,
b1_0.nation,
p1_0.created_at,
p1_0.eu_standard,
p1_0.us_standard,
p1_0.image_url,
p1_0.modified_at,
p1_0.name,
p1_0.purchase_link
from
pet_food p1_0
join
brand b1_0
on b1_0.id=p1_0.brand_id
where
b1_0.name in (?,?)
and p1_0.us_standard=?
and exists(select
1
from
pet_food_primary_ingredient p2_0
join
primary_ingredient p3_0
on p3_0.id=p2_0.primary_ingredient_id
where
p3_0.name in (?,?)
and p1_0.id=p2_0.pet_food_id)
and exists(select
1
from
pet_food_functionality p4_0
join
functionality f1_0
on f1_0.id=p4_0.functionality_id
where
f1_0.name in (?,?)
and p1_0.id=p4_0.pet_food_id)
order by
p1_0.id desc limit ?
소량의 데이터일 때는 이런 심각한 상황인 줄 몰랐고 시간도 얼마 안 걸렸기 때문에 눈치를 못 챘었다. 저 warn 부분도 로그들 사이에 작게 있어서 보이지도 않았다. 해당 부분을 수정했을 때 6초까지 줄어들었다. 그만큼 대량의 데이터를 애플리케이션 단으로 가져오는데 비용이 많이 든다. 제대로 체감했으니 앞으로 이런 실수는 하지 않을 것 같다!

DTO로 필요한 것만
하지만, 6초도 굉장히 오래 걸린다고 생각한다. 더 줄여보자. 현재 우리 쿼리의 projection 부분을 보면 매우 많다.
p1_0.id,
p1_0.brand_id,
b1_0.id,
b1_0.created_at,
b1_0.founded_year,
b1_0.has_research_center,
b1_0.has_resident_vet,
b1_0.image_url,
b1_0.modified_at,
b1_0.name,
b1_0.nation,
p1_0.created_at,
p1_0.eu_standard,
p1_0.us_standard,
p1_0.image_url,
p1_0.modified_at,
p1_0.name,
p1_0.purchase_link
하지만, 우리 프론트 화면에 필요한 부분은 petFood.id, petFood.name, brand.name, petFood.imageUrl 이 4개밖에 필요 없다. 불필요한 정보는 제거하고 필요한 것만 받아서 DTO로 받아보자.
queryFactory
.select(new QGetPetFoodQueryResponse(
petFood.id,
petFood.name,
brand.name,
petFood.imageUrl)
)
.from(petFood)
.join(petFood.brand, brand)
.where(
isLessThan(lastPetFoodId),
isContainBrand(brandsName),
isMeetStandardCondition(standards),
isContainPrimaryIngredient(primaryIngredientList),
isContainFunctionalities(functionalityList)
)
.orderBy(petFood.id.desc())
.limit(size)
.fetch();
QueryDsl 빈 생성 방법 중 QueryProjection을 이용해 4가지 필드로만 이루어진 DTO를 반환해 주었고 그렇게 6초에서 3.71초까지 줄게 되었다.

인자를 이름에서 id로 받아 조인 테이블 줄이기
현재 쿼리의 where을 보면 서브 쿼리들이 나가고 있는데 그 서브 쿼리에서도 join이 일어나고 있다. join이 일어나는 이유는 해당 필터는 id가 아니고 이름(String)으로 받고 있기 때문이다. 해당 테이블의 관계는 다대다(펫 푸드 - 중간 테이블 - 해당 테이블)인데 중간 테이블에는 이름이 없기 때문에 해당 테이블까지 조인이 발생하여 비용이 추가된다.
select
p1_0.id,
p1_0.name,
b1_0.name,
p1_0.image_url
from
pet_food p1_0
join
brand b1_0
on b1_0.id=p1_0.brand_id
where
b1_0.name in (?,?)
and p1_0.us_standard=?
and exists(select
1
from
pet_food_primary_ingredient p2_0
join
primary_ingredient p3_0
on p3_0.id=p2_0.primary_ingredient_id
where
p3_0.name in (?,?)
and p1_0.id=p2_0.pet_food_id)
and exists(select
1
from
pet_food_functionality p4_0
join
functionality f1_0
on f1_0.id=p4_0.functionality_id
where
f1_0.name in (?,?)
and p1_0.id=p4_0.pet_food_id)
order by
p1_0.id desc limit ?
이름으로 받고 있는 필터(주원료, 기능성)들을 id로 받도록 수정해보자.
//before
private BooleanExpression isContainFunctionalities(List<String> functionalityList) {
if (functionalityList.isEmpty()) {
return null;
}
return petFood.petFoodFunctionalities.any()
.functionality.name.in(functionalityList);
}
//after
private BooleanExpression isContainFunctionalities(List<Long> functionalityList) {
if (functionalityList.isEmpty()) {
return null;
}
return petFood.petFoodFunctionalities.any()
.functionality.id.in(functionalityList);
}
인자를 이름에서 id로 바꿔서 불필요한 조인을 줄였고 3.71초에서 2.56초로 감소한 걸 확인할 수 있다.

복합 인덱스로 커버링 인덱스
이제 쿼리는 더 이상 뭘 건드려야 될지 안 보여서 EXPLAIN을 이용해 쿼리 실행 계획을 살펴봤다.

기존의 테이블 말고도 2개의 MATERIALIZED가 생성되었다. MATERIALIZED는 MySQL 5.6 버전에 추가된 셀렉트 타입으로 서브 쿼리를 임시테이블로 만들어 조인을 하는 형태로 최적화를 해준다고 한다. 최적화를 해주긴 하지만 임시 테이블을 만든다는 거 자체가 비용이 들 것이다. 또한, Using index도 아니고 Using index condition은 뭘까? 인덱스를 사용하여 테이블에서 행을 검색하는 경우를 위한 최적화 기능인데 자세한 내용은 다음 포스트를 참고하자.
이를 좀 더 개선하여 커버링 인덱스로 만들어보자. Using Index로 만들기 위해 현재 서브 쿼리에 있는 fk들을 복합 인덱스로 엮어 추가해 줄 수 있다.
Using Index: 데이터 파일을 전혀 읽지 않고 인덱스만 읽어서 쿼리를 처리하여 매우 빠름
현재 두 개의 서브 쿼리는 다음과 같다.
select 1 from pet_food_primary_ingredient p2_0
where p2_0.primary_ingredient_id in (?,?) and p1_0.id=p2_0.pet_food_id
select 1 from pet_food_functionality p4_0
where p4_0.functionality_id in (1,2) and p1_0.id=p4_0.pet_food_id
CREATE INDEX를 이용해 각 관계에 인덱스를 걸어주면 된다.
CREATE INDEX idx_pet_food_primary_ingredient on pet_food_primary_ingredient(pet_food_id, primary_ingredient_id);
CREATE INDEX idx_pet_food_functionality on pet_food_functionality(pet_food_id, functionality_id);
이렇게 하여 임시 테이블도 삭제되었고 커버링 인덱스도 걸렸다.

그럼, 최종적으로 시간이 얼마나 걸리는지 보자! 최종적으로 10초 -> 0.662초로 개선되었다. 쿼리를 개선하는 과정이 정말 신선했고 재밌었지만 시간이 정말 오래 걸렸고 그만큼 너무 힘들었다…ㅠㅠ 개선해 보면서 정말 어려운 용어도 많았고 스킵 한 내용도 많은 거 같은데 Real My SQL을 읽어보면서 다시 한번 정리하는 시간을 가져야겠다.

*틀린 부분이 있으면 언제든지 말씀해 주시면 공부해서 수정하겠습니다.