동시성 문제 해결을 위한 고민
How to resolve concurrency when it happens
현재 우리 집사의고민 반려동물 식품 리스트 view이다. 만약에 앞으로 추가적인 고도화를 한다면 해당 view에 좋아요 수, 평점, 댓글 수 등을 보여줄 수 있을 것이다. 해당 view는 사용자가 가장 많이 호출하는 메인 페이지의 API이기도 하다. 그래서 나중에 트래픽이 많아지면 해당 로직을 구현할 때 성능 개선을 위해 통계 컬럼을 식품 엔티티에 충분히 추가해줄 수도 있을 것 같다.
하지만, 이렇게 하게 되면 데이터의 정합성이 안 맞을 수 있는 가능성이 생길 수 있다. 예를 들어 두 명의 사용자가 동시에 해당 식품에 좋아요를 했다고 가정해 보면 다음과 같은 상황이 일어날 수 있다. (참고로 JPA를 사용하고 있다.)
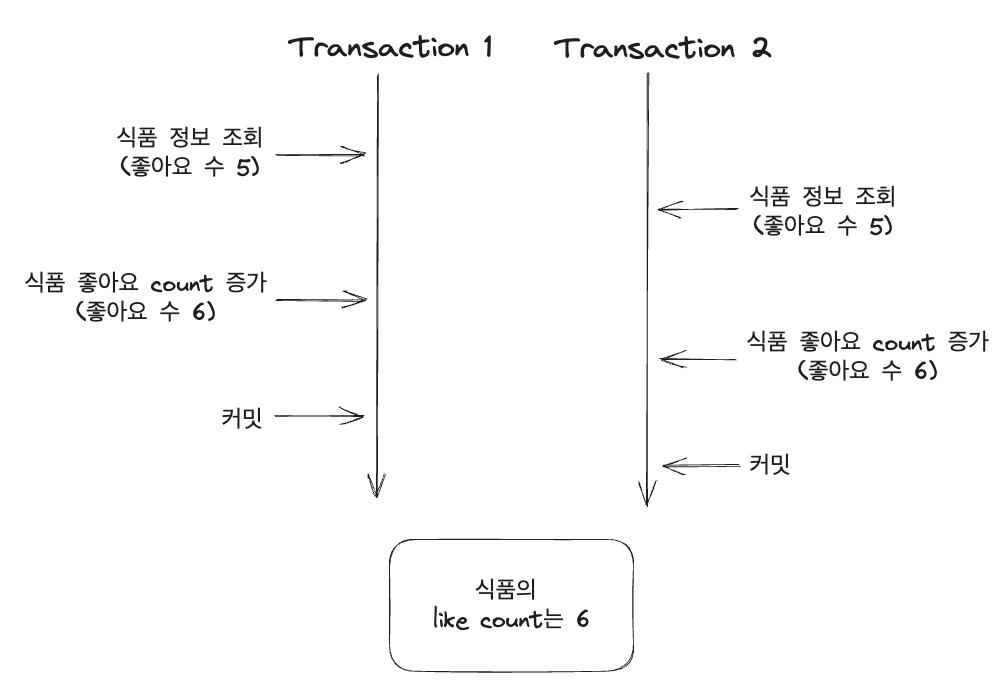
두 사용자가 한 식품에 대해 좋아요를 눌러서 해당 식품의 좋아요 수는 7개가 되어야 하지만 조회한 시점에 카운트로 5를 읽고 서로 1씩 증가를 해버렸기 때문에 결과적으로 6이 되어버렸다. 이를 갱실 분실 문제라고 한다. 어떻게 해결해 볼 수 있을까?
우선 대표적으로 낙관적 락이나 비관적 락이 생각나긴 하는데 근본적인 문제가 무엇인지부터 살펴보고 다른 방법이 있나 고민해 보자.
직접 Update
update 하는 과정을 잘 분석해 보면 JPA의 변경 감지를 사용하고 있기 때문에 동시성 문제가 일어나는 걸 알 수 있다. 변경 감지의 경우 바로바로 데이터베이스 값을 수정하는 것이 아니라 커밋 하는 시점에 flush가 일어나 쿼리가 날아가게 된다. 그래서 한 트랜잭션에서 select와 update 하는 사이에 누군가가 동시에 select 하고 update 하게 되면 갱실 분실이 일어난다.
그렇기 때문에, 변경 감지를 포기하고 직접 update 문을 날려주어서 정합성을 맞춰줄 수도 있다. update 문의 경우 x lock이 걸리기 때문에 해당 부분에서 다음과 같은 과정이 일어나 동시성이 발생하지 않는다.
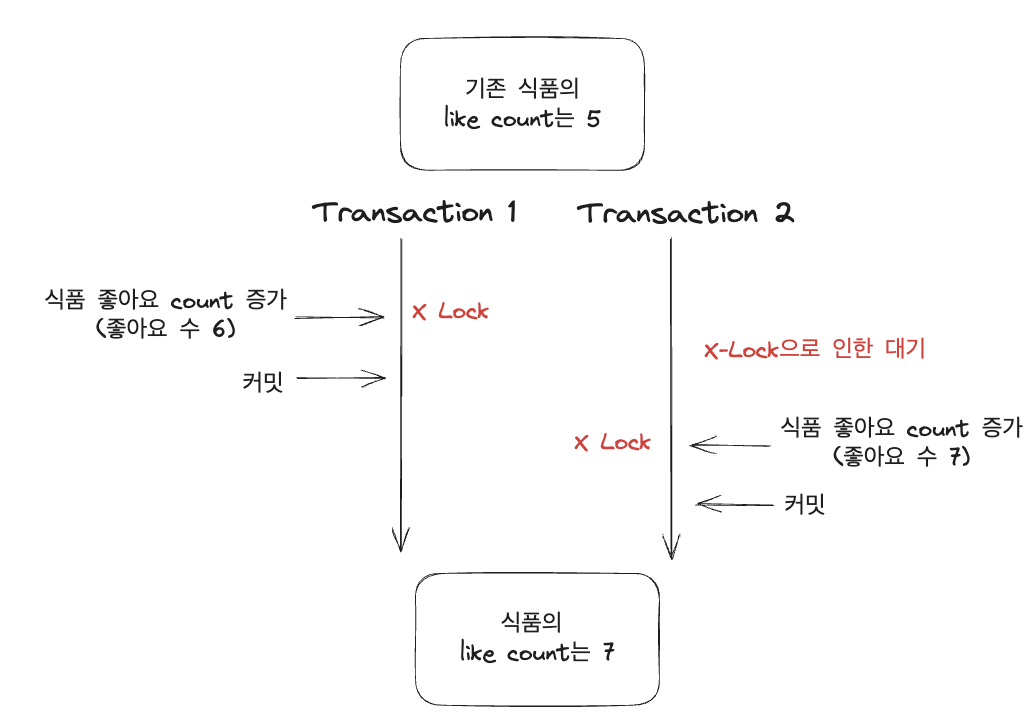
즉, 다음과 같이 jpql을 이용해 해당하는 카운트의 개수를 증가시켜주는 리포지토리 메서드를 생성 후 서비스에서 직접 호출해 주면 된다. 이 방법의 경우 직접 쿼리를 이용해 데이터의 값을 변경 시켜주기 때문에 객체지향적이지는 않지만 성능 저하를 최소화하며 정합성을 지킬 수 있기 때문에 trade off로 충분히 감안해서 사용해 볼 수 있을 것 같다.
@Query(value = "update PetFood p set p.likeCount = p.likeCount + 1 where p.id = :petFoodId")
void increaseLikeCount(Long petFoodId);
근데 위의 코드로 실행하게 되면 다음과 같은 에러가 뜨게 된다.
org.springframework.dao.InvalidDataAccessApiUsageException: org.hibernate.hql.internal.QueryExecutionRequestException: Not supported for DML operations …
공식 문서를 보면 @Query를 이용해서 INSERT, UPDATE, DELETE 같은 쿼리를 사용할 때는 해당 애노테이션을 사용하라고 되어있다.
해당 문서의 추가 옵션을 보면 clearAutomatically와 flushAutomatically가 있는데 애네는 뭘까? 우선 각 정의는 다음과 같다.
- clearAutomatically: 수정 쿼리를 실행한 후 기본 지속성 컨텍스트를 지워야 하는지 여부
- flushAutomatically: 수정 쿼리를 실행하기 전에 기본 지속성 컨텍스트를 플러시 해야 하는지 여부
음.. 그냥 @Modifying만 사용하면 안 되는 걸까?
@Modifying
@Query(value = "update PetFood p set p.likeCount = p.likeCount + 1 where p.id = :petFoodId")
void increaseLikeCount(Long petFoodId);
위처럼 하고 실행하면 잘 실행되긴 한다. 하지만, 실행하고 난 뒤 데이터 베이스의 값과 영속성 컨텍스트의 값이 일치하지 않는 걸 목격할 수 있다. 왜냐하면 @Query로 정의된 JPQL은 영속성 컨텍스트를 거치는 게 아니라 바로 Database로 쿼리를 날리기 때문에 데이터베이스 값은 증가되어 있지만, 영속성 컨텍스트의 값은 그대로이다. 해당 id로 데이터베이스에서 다시 값을 가져오더라도 이미 영속성 컨텍스트에 같은 id로 저장되어 있는 값이 있기 때문에 무시한다.(영속성 컨텍스트가 우선순위이기 때문에)
@Modifying(clearAutomatically = true)
@Query(value = "update PetFood p set p.likeCount = p.likeCount + 1 where p.id = :petFoodId")
void increaseLikeCount(Long petFoodId);
그래서 위처럼 clearAutomatically를 사용해서 @Query로 정의된 JPQL이 실행된 후에 자동으로 영속성 컨텍스트를 비어줄 수 있다. flushAutomatically는 플러시와 관련이 있는 거 같은데 언제 사용하는 걸까? JPA에서 플러시가 일어날 수 있는 상황은 다음과 같다.
- flush() 직접 호출
- 트랜잭션 커밋 시
- JPQL 쿼리 실행 시
분명 JPQL 쿼리가 실행되면 플러시가 자동으로 호출된다고 들었다. 근데 왜 필요한지 궁금해졌다. 그래서 Spring Data Jpa Github Repo에 들어가서 issue에 검색을 해봤더니 다음과 같은 issue가 있었다. 해당 이슈를 보면 원래 clearAutomatically라는 옵션만 있었고 flushAutomatically는 없었던 것 같다.
근데 clearAutomatically만 달고 사용하다 보니 다음과 같은 이슈가 있었다고 한다.
As stated in the reference documentation, the AUTO flush strategy may sometimes synchronize the current persistence context prior to a query execution.
참조 문서에 명시된 바와 같이, 자동 플러시 전략은 때때로 쿼리 실행 전에 현재 지속성 컨텍스트를 동기화할 수 있습니다.
The clearAutomatically property drops all the pending changes in the EntityManager that are not related to the current update query (cause they are not automatically flushed).
clearAutomatically 속성은 현재 업데이트 쿼리와 관련이 없는(자동으로 플러시되지 않기 때문에) EntityManager의 보류 중인 모든 변경 사항을 삭제합니다.
That’s why I’m asking for a new property to force the EntityManager to flush changes
그렇기 때문에 새 속성을 요청하여 EntityManager가 변경 사항을 강제로 플러시하도록 하려고 합니다.
즉, 작성한 JPQL 쿼리와 관련된 엔티티만 자동으로 flush가 되고 나머지 엔티티는 자동으로 flush가 되지 않고 clearAutomatically 속성에 의해 삭제되어서 데이터베이스에 반영이 되지 않고 있던 것이다. 예를 들어, 우리의 likeCount와 관련한 PetFood 엔티티는 플러시가 되지만, Like 엔티티는 플러시 되지 않고 영속성 컨텍스트에서 지워진다.
그렇기 때문에 다음과 같이 flushAutomatically도 true로 설정해서 사용해 줘야 원하는 데로 작동할 수 있다.
@Modifying(clearAutomatically = true, flushAutomatically = true)
@Query(value = "update PetFood p set p.likeCount = p.likeCount + 1 where p.id = :petFoodId")
void increaseLikeCount(Long petFoodId);
Lock 기법 vs 트랜잭션 격리 수준
동시성 하면 Lock(낙관적 락, 비관적 락)이나 트랜잭션 격리 레벨 같은 키워드가 떠오르는데 둘은 어떤 차이일까? Lock은 특정한 데이터에 대한 동시 액세스를 방지하기 위한 매커니즘이고 트랜잭션 격리 수준은 트랜잭션 동안 읽기 일관성을 어떻게 처리할지에 대한 전략이다.
즉, Lock은 낙관적 락, 비관적 락을 이용해 다른 트랜잭션이 동일한 레코드를 업데이트하는 것을 막기 위한 방법으로 트랜잭션 격리 수준과는 관계가 없다. 또한, 트랜잭션 격리도 다음과 같은 네 가지 트랜잭션 격리 수준으로 Lock 과는 관련이 없다.
- READ UNCOMMITTED: 각 트랜잭션의 변경 내용이 다른 트랜잭션에서 조회되는 격리 수준
- READ COMMITTED: 커밋이 완료된 트랜잭션의 변경사항만 다른 트랜잭션에서 조회되는 격리 수준
- REPETABLE READ: 트랜잭션이 시작되기 전에 커밋 된 내용만 조회되는 격리 수준
- SERIALIZABLE: 사용중인 레코드가 다른 트랜잭션에서 접근할 수 없는 격리 수준
우리가 사용하고 있는 MySQL의 기본 격리 수준은 REPEATABLE READ이다. MariaDB의 경우도 마찬가지이고 오라클은 READ COMMITTED을 사용한다. 현재 사용하고 있는 트랜잭션 격리 레벨을 높이면 해결할 수 있을까? 한 단계 위인 SERIALIZABLE을 적용하고 나면 일어나는 과정들을 한번 보자.
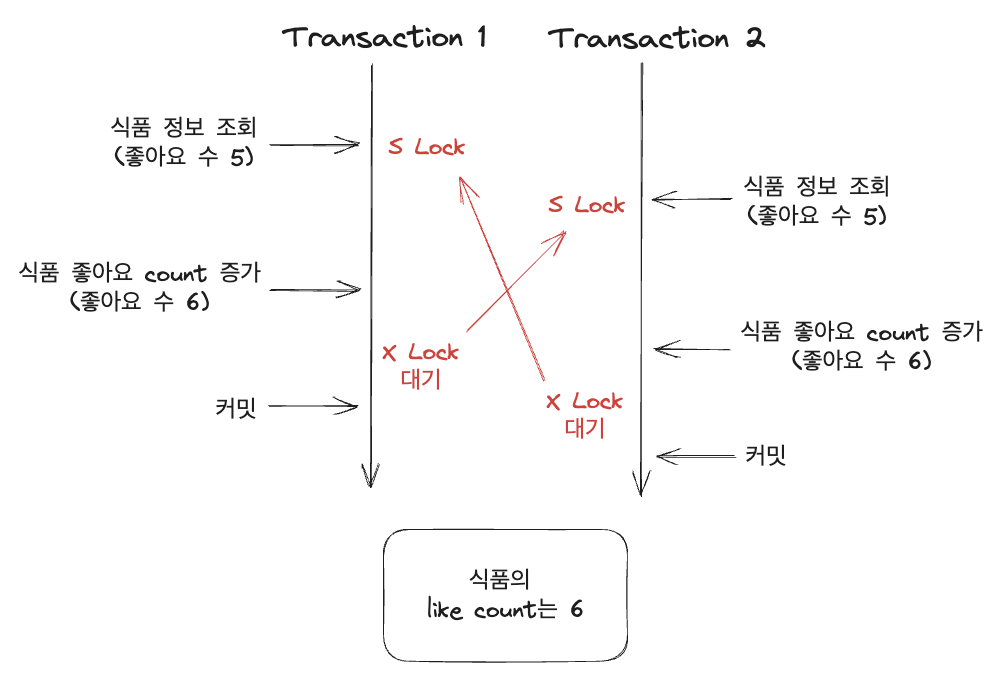
우선 각각의 트랜잭션에서 조회를 할 때 S Lock(Shared Lock) 이 걸리게 된다. 이후 카운터를 증가시키기 위해 update 쿼리가 날아간다. 이때 Transaction 1에서 값을 변경시키기 위해 X Lock(Exclusive Lock) 을 얻어야 되는데 Transaction 2에서 공유 락을 가지고 있기 때문에 대기 상태로 들어가게 된다. Transaction 2도 마찬가지로 값을 변경시키기 위해 X Lock을 얻어야 되어서 대기 상태로 들어가게 되어서 서로 데드락에 빠지게 된다. 즉, 트랜잭션 격리 레벨로는 이 문제를 해결할 수 없기 때문에 다른 방법을 찾아봐야 된다.
낙관적 락(Optimistic Lock)
낙관적 락은 트랜잭션들의 빈번한 충돌이 일어나지 않을 것이라고 가정하는 방법으로 데이터베이스의 락을 사용하지 않고 애플리케이션 레벨에서 동시성을 제어하는 방법이다. 별도의 락을 잡지 않으므로 비관적 락보다 성능상 이점이 있다. 애플리케이션 레벨에서 어떻게 처리한다는 걸까?
바로, 엔티티의 Version을 통해서 관리하는데 JPA 같은 경우 @Version 애노테이션을 이용해 쉽게 사용해 볼 수 있다.
@Entity
class PetFood {
...
@Version
private Integer version
}
해당 엔티티가 변경될 때마다 version이 증가하는 방식이고 동작 과정은 다음과 같다.
- Transaction1에서 식품 정보를 조회(좋아요 0, version 0)
- Transaction2에서 식품 정보를 조회(좋아요 0, version 0)
- Transactoin1에서 좋아요 Count 증가 (version 0으로 update 쿼리 -> 좋아요 1, version 1)
- Transactoin2에서 좋아요 Count 증가 (version 0으로 update 쿼리 날리지만 version0의 해당 식품은 없기 때문에 예외 발생)
충돌 시 ObjectOptimisticLockingFailureException 예외가 터지기 때문에 해당 예외를 잡아서 개발자가 직접 처리해주어야 한다. 해당 식품에 좋아요를 누르는 게 선착순처럼 동시에 수많은 트래픽이 몰리지도 않을 것 같아 충돌이 빈번하게 일어나진 않을 것 같다.(소규모 서비스이면 더더욱 더) 그래서 몇 번의 재시도 로직을 추가해 주거나 예외를 보내 다시 누르도록 처리해 줄 수도 있을 것 같다.
하지만, 위에서 FK가 개입되게 된다면 상황이 달라진다. 위에서 보여준 문제 상황을 좀 더 상세하게 봐보자. 사실, 좋아요 Entity가 Insert 되는 과정이 있었지만 위에서는 딱히 중요하지 않은 거 같아 생략했었다. 어떤 문제가 있다는 걸까?
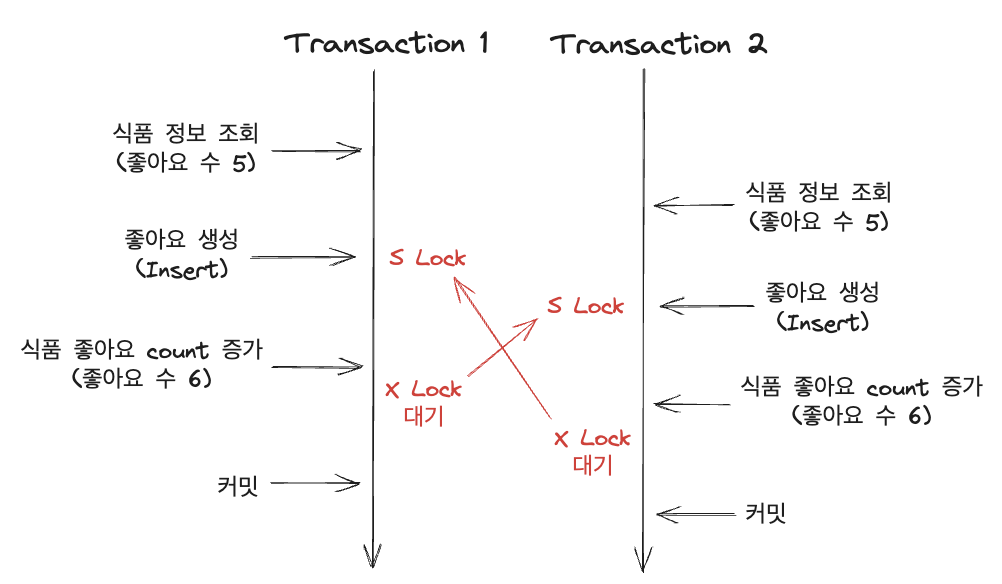
공식 문서를 보면 다음과 같은 내용이 있다.
MySQL extends metadata locks, as necessary, to tables that are related by a foreign key constraint. … For foreign key checks, a shared read-only lock (LOCK TABLES READ) is taken on related tables.
MYSQL은 필요에 따라 외래 키 제약 조건과 관련된 테이블로 잠금을 확장한다 … 외래 키 확인을 위해 관련 테이블에 공유 읽기 전용(S Lock) 잠금이 적용된다.
즉, 좋아요를 생성하는 Insert 쿼리를 날릴 때 식품에 대한 S Lock이 걸리게 된다. 트랜잭션 1, 2에서 처음에 서로 S Lock이 걸리고 그 후에 count를 증가시키는 update를 날릴 때는 아까와 같이 서로 대기하게 되어 데드락이 발생하는 문제가 생기는 것이다. 그래서 해당 방법을 사용하고자 하면 외래 키 제약 조건을 없애는 방법이 있을 수 있겠다.
비관적 락(Pessimistic Lock)
비관적 락은 트랜잭션들의 빈번한 충돌이 발생할 것이라고 가정하는 방법으로 데이터베이스의 락을 사용해서 동시성을 제어하는 방법이다. 위에서 현재 FK로 인해 서로 데드락이 걸려있는 상황이다. 이때, 비관적 락을 이용하여 해결해 보자. 해결하려는 과정은 다음과 같다.
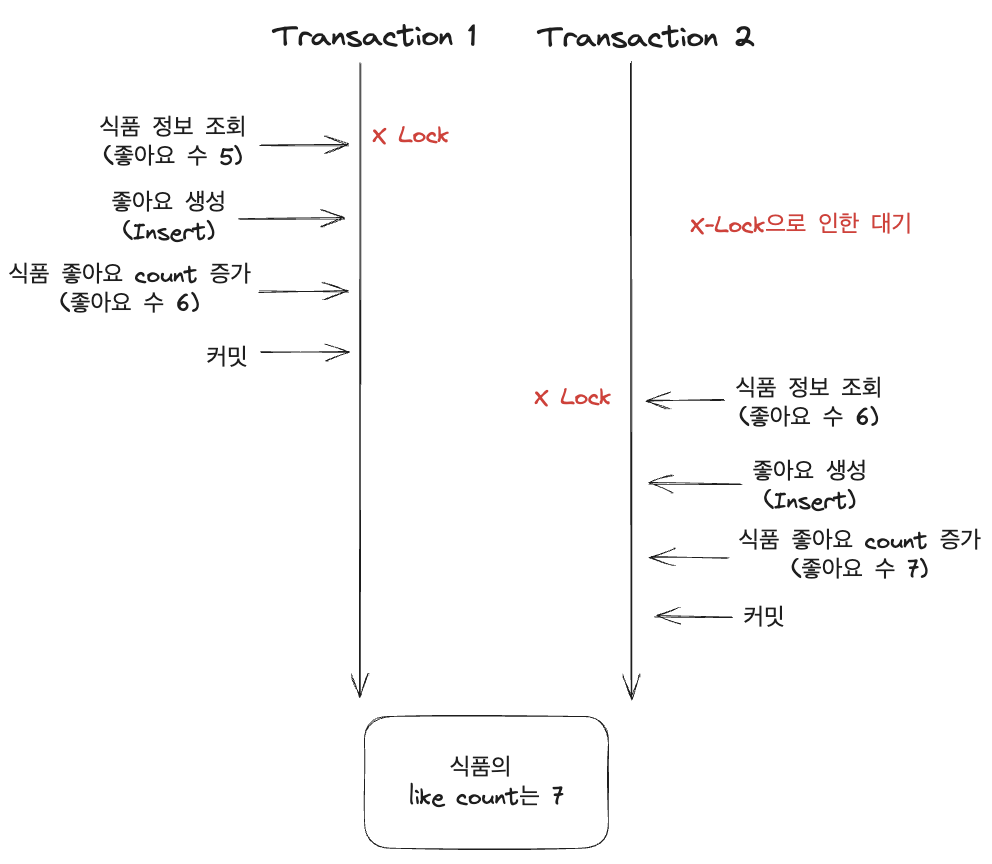
트랜잭션 1에서 조회할 때 비관적 락을 걸어주면 해당 트랜잭션이 커밋 또는 롤백이 될 때까지 X Lock을 얻게 되어 다른 트랜잭션에서 해당 레코드에 접근 자체를 할 수가 없게 된다. 즉, 트랜잭션 A의 과정이 완전히 끝나고 나서야 B가 실행되기 때문에 데이터의 정합성과 위에서의 FK 데드락 문제가 해결되게 된다.
비관적 락의 경우도 @Lock 애노테이션을 통해 적용해 줄 수 있다. 식품 정보를 조회하는 메서드에 @Lock(LockModeType.PESSIMISTIC_WRITE)을 붙여 조회할 때 X Lock을 걸 수 있게 해주면 된다.
@Lock(LockModeType.PESSIMISITC_WRITE)
PetFood findByIdForUpdate(Long id)
하지만, 하나의 트랜잭션이 끝날 때까지 다른 트랜잭션은 대기만 하기 때문에 많은 트랜잭션이 접근하는 경우 성능에 큰 이슈가 있을 것으로 예상된다. 얼마 전에 애쉬가 비관적 락으로 선착순 티켓 동시성을 해결한 글이 있는데 해당 글을 보고 시니어 분들의 멘션이 있었다. (역시 절대 고수 애쉬ㄷㄷ 부럽따.., 정말 잘 썻으니 한 번씩 읽어보자 👍🏻)
뭔가 최대한 다른 방법으로 해결할 수 있는 방법을 모색하면 좋을 것 같다는 이야기들을 많이 하셨다. 이 부분에 대해서는 시간이 나면 성능 테스트를 한번 해봐야겠다. 그래서 비관적 락도 일단 보류!
마무리하기 전에 아래 내용을 한번 읽어 보고 자신이 낙관적 락과 비관적 락을 잘 이해했는지 생각해 보자.
낙관적 락의 경우 트랜잭션을 커밋하기 전까지는 충돌 여부를 확인할 수 없다.
비관적 락의 경우 데이터 수정시 트랜잭션 즉시 트랜잭션 충돌여부를 알 수 있다.
정리
지금 현재 상황에서는 생각해 본 방법 중 첫 번째 방법이었던 직접 Update하는 방법이 가장 괜찮을 것 같다. 물론 아직 여기까지 프로젝트가 고도화되진 않았기 때문에 적용은 못하겠지만 앞으로 해당 문제와 관련된 상황을 만나게 된다면 좀 더 능숙하게 대처해 볼 수 있지 않을까 한다.
문제를 해결하는 과정은 다시 한번 정말 흥미롭다는 걸 느꼈고 해당 문제뿐 아니라 그걸 기반하는 지식들도 조금씩 더 깊게 배운 느낌이라 보람찼던 고민이었던 것 같다. 그리고 다시 한번 생각나는 “은 탄환은 없다”…
*틀린 부분이 있으면 언제든지 말씀해 주시면 공부해서 수정하겠습니다.