좀 더 우아하게 유지보수 가능한 테스트 코드로 개선하기
Improve to more elegant maintainable test code

현재 우리 집사의고민팀 테스트 코드 커버리지는 90%정도 된다. 이 영광을 jacoco형님께 바친다. 물론, 높은 커버리지가 무조건 최고는 아닌 게 assertion으로 확인하지 않고 그냥 선언만 해도 단순히 높일 수도 있기 때문이다. 하지만, 높은 커버리지가 시스템을 제대로 테스트했다는 것을 의미하지는 않지만, 커버리지가 매우 낮다는 것은 시스템이 제대로 테스트되지 않았다는 것을 의미하기 때문에 최대한 높이는 것이 좋지 않을까?
Jacoco: Java 코드의 커버리지를 체크하는 라이브러리
어쨌든, 이게 요점이 아니고 이렇게 테스트 코드가 점점 많아짐에 따라 테스트코드도 점점 관리할 필요를 느꼈다. 점점 프로덕션 코드가 늘어갈수록 테스트 코드도 늘어가는데 보통 테스트 코드에는 큰 신경들을 안 쓰는 게 느껴졌다. 물론, 나도 그랬고 그래서 테스트 코드를 펼쳐 볼 때마다 솔직히 불편했다.
테스트는 굉장히 중요하다고 생각한다. 테스트가 있기 때문에 우리가 좀 더 안심하고 프로덕션 코드를 짤 수 있고 리팩터링도 수월하게 할 수 있다. 그리고 테스트 코드가 팀의 문서라고 할 수도 있다. 테스트 코드를 이용해 복잡한 비즈니스 로직을 좀 더 쉽게 이해할 수 있기 때문이다.
그렇기 때문에 언제까지 이 친구랑 불편하게 살 수는 없다. 앞으로 좀 더 잘 지내볼 수 있게 유지 보수 가능한 테스트 코드로 개선해 보자.

적용하고 있는 것
먼저 현재 적용하고 있는 것 중 다음 프로젝트에도 적용해 보면 좋은 것들을 몇 개 적어보겠다.
테스트 작명 한글화 적용
나는 원래 테스트를 영어로만 작성했고 한글에 거부감을 가졌던 사람 중 한 명이다. 하지만, 최근에는 학습 측면에서 여러 가지 경험하면 좋을 것 같아 이번 프로젝트에서 한글을 사용하고 있는데 인식이 정말 많이 바뀌었다.
우선, 불편할 것 같았던 자동완성 기능도 크게 불편하지는 않았다. 웬만하면 변수명이 다 짧았으며 긴 경우 _을 입력하면 똑같이 사용할 수 있다. 테스트가 한글로 되어 있어 가독성이 전체적으로 크게 향상된 것이 이 단점을 덮고도 남을 장점이 아닌가 한다.
// given
var 모든_영양기준_만족_식품 = 모든_영양기준_만족_식품(brandRepository.save(아카나_식품_브랜드_생성()));
식품_기능성_추가(모든_영양기준_만족_식품, functionalityRepository.save(기능성_다이어트()));
식품_기능성_추가(모든_영양기준_만족_식품, functionalityRepository.save(기능성_튼튼()));
식품_주원료_추가(모든_영양기준_만족_식품, primaryIngredientRepository.save(주원료_닭고기()));
petFoodRepository.save(모든_영양기준_만족_식품);
var 요청_준비 = given(spec)
.queryParam("size", 20)
.filter(성공_API_문서_생성("식품 필터링 없이 조회 - 성공(전체 조회)"));
// when
var 응답 = 요청_준비.when()
.get("/pet-foods");
// then
응답.then()
.assertThat().statusCode(OK.value());
이제 진짜 테스트가 프로젝트의 스펙이 된 것이다. 하나하나 해석할 필요 없이 그냥 한글로 된 시나리오를 읽듯 자연스럽게 내려오면 된다. 영어로 되었을 때는 로직을 읽기 전에 머리를 한 번 더 거쳐야 되었지만 이제 직관적인 구성으로 한층 더 테스트와 가까워 질 수 있지 않을까. 물론, 오픈소스나 외국인과 같이하는 프로젝트에서는 사용하긴 좀 어려워 보인다.
또한, 위에서 RestAssured의 Request 부분을 다음과 같이 픽스처로 빼서 좀 더 확장성 있게 사용 해 줄 수도 있을 것 같다.
public static ExtractableResponse<Response> GET_요청(String url) {
return RestAssured.given()
.when()
.get(url)
.then()
.extract();
}
public static ExtractableResponse<Response> PUT_요청(String url, Object body) {
return RestAssured.given()
.contentType(MediaType.APPLICATION_JSON_VALUE)
.body(body)
.when()
.put(url)
.then()
.extract();
}
Fixture
계속해서 given 코드를 짜다 보면 중복해서 생성되는 데이터들이 나온다. 이 중복을 제거하기 위해 Fixture를 사용해 볼 수 있다.
public static PetFood 모든_영양기준_만족_식품(Brand brand) {
return builder()
.name("모든 영양기준 만족 식품")
.purchaseLink("purchaseLink")
.imageUrl("imageUrl")
.brand(brand)
.hasStandard(HasStandard.builder().unitedStates(true).europe(true).build())
.reviews(new Reviews())
.build();
}
Fixture를 생성하기 위해 팩토리 메서드를 사용할 수도 있지만 팩토리 메서드 같은 경우 프로덕션 코드에서 어떤 의도를 가지고 만든 거기 때문에 최대한 지양하고 순수한 생성자나 빌더가 더 좋다.
Nested
프로젝트가 점점 커져갈수록 테스트 코드도 커져간다. 수많은 테스트 중 특정한 테스트의 수행 결과들을 찾기가 어렵다. 이때, Nested 애노테이션을 이용하여 테스트를 다음과 같이 계층형으로 구성할 수 있다.
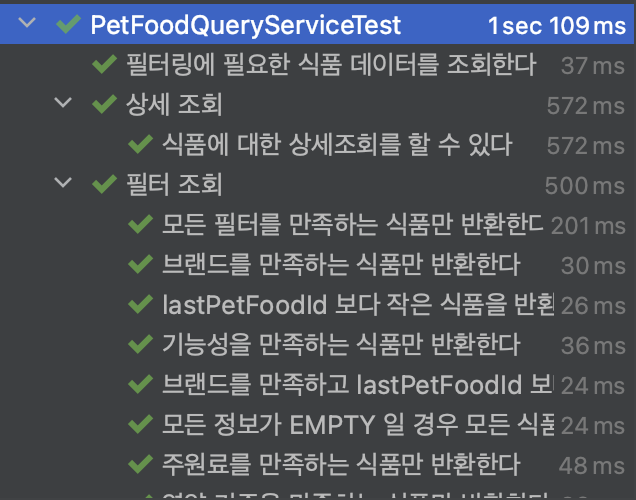
같은 관심사의 테스트를 모아둘 수 있기 때문에 내가 원하는 테스트를 열어서 수행 결과들을 볼 수 있어 테스트 가독성이 향상되어 보기 한층 더 편했다.
ParameterizeTest
여러 가지 인자 값들을 테스트하고 싶은데 여러 개의 메서드들을 생성하기는 비용이 너무 커진다. 하나의 메서드에서 모든 인자 값들을 테스트해 볼 수 없을까?
@ParameterizedTest
@MethodSource("별점과_평균_리스트_만들기")
void 식품의_평균_별점을_계산할_수_있다(List<Integer> 별점_리스트, double 예상_결과) {
// given
Reviews 리뷰리스트 = 별점으로_리뷰만들기(별점_리스트);
// when
double 계산_결과 = 리뷰리스트.calculateRatingAverage();
// then
assertThat(계산_결과).isEqualTo(예상_결과);
}
private static Stream<Arguments> 별점과_평균_리스트_만들기() {
return Stream.of(
Arguments.of(emptyList(), 0),
Arguments.of(List.of(1, 2, 3, 4, 5), 3.0),
Arguments.of(List.of(2, 3, 3, 5, 5), 3.6),
Arguments.of(List.of(1, 2, 4), 2.3),
Arguments.of(List.of(4, 4, 4, 5, 5), 4.4),
Arguments.of(List.of(1, 2, 5), 2.7)
);
}
위와 같이 해당 method를 이용한 @MethodSource로도 가능하고 @ValueSource, @CsvSource 등 여러 가지 ParameterizeTest를 적극적으로 이용해 보자.
개선하려는 것
데이터 셋팅
각 테스트마다 데이터가 필요했었고 해당 데이터는 연관관계가 많았기 때문에 이를 각각의 테스트마다 적어주기는 너무 불편했어서 기존에는 이를 setUp으로 구성해 줬었다.
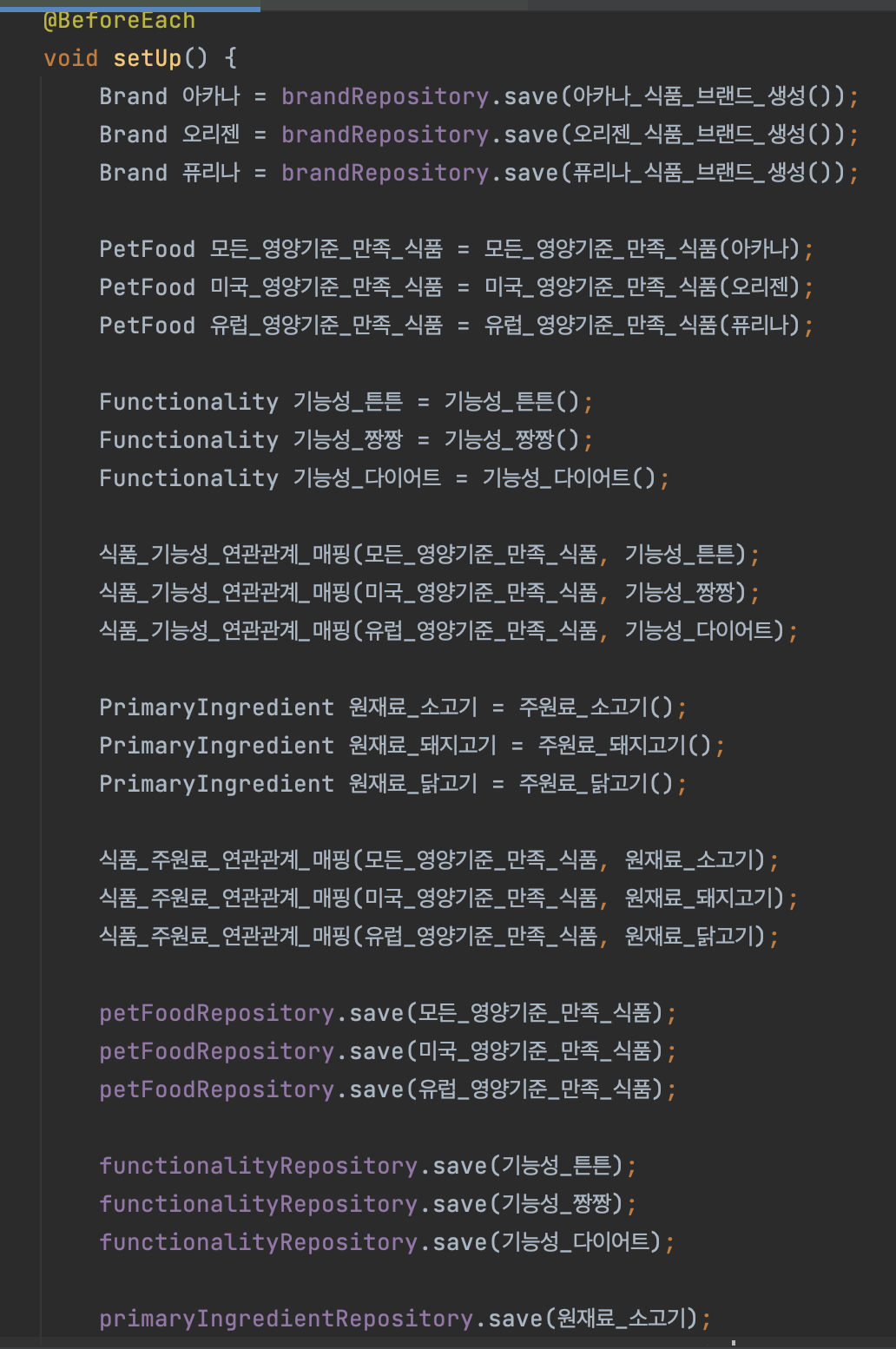
하지만, 이 부분은 개선할 때 제일 먼저 고치고 싶은 것 중 하나였다. 어떤 테스트이든지 처음에 데이터가 위처럼 세팅되어 있으니깐 해당 데이터에 영향을 안 받을 수가 없다. 새로 추가한다 해도 이미 beforeEach에서 데이터가 들어가서 영향을 받아 매우 불편했다. 즉, 모든 테스트에 결합성이 생긴 것이다.
위의 공통 데이터들은 테스트와 결합도가 생겨 이 데이터들을 수정하는 경우에 모든 테스트에 공통으로 영향을 줄 수 있기 때문에 지양하는 것이 좋을 것 같다.
또한, 테스트 클래스가 엄청 커졌을 때 아래에 있는 어떤 테스트를 파악해야 된다고 가정을 해보자. 해당 테스트의 given이 없기 때문에 setUp을 보기 위해 위, 아래 왔다 갔다 해야 되는데 이는 과연 문서로서의 역할을 할 수 있을까? (마찬가지로, 테스트를 작성할 때도 불편)
이를 각 테스트마다 생성할 수 있도록 분리해 주었고 픽스처를 이용해 최소한의 중복으로 할 수 있도록 작성해주었다.
//given
PetFood 모든_영양기준_만족_식품 = 모든_영양기준_만족_식품(brandRepository.save(아카나_식품_브랜드_생성()));
PetFood 미국_영양기준_만족_식품 = 미국_영양기준_만족_식품(brandRepository.save(오리젠_식품_브랜드_생성()));
PetFood 유럽_영양기준_만족_식품 = 유럽_영양기준_만족_식품(brandRepository.save(퓨리나_식품_브랜드_생성()));
식품_기능성_추가(모든_영양기준_만족_식품, functionalityRepository.save(기능성_튼튼()));
식품_기능성_추가(미국_영양기준_만족_식품, functionalityRepository.save(기능성_짱짱()));
식품_기능성_추가(유럽_영양기준_만족_식품, functionalityRepository.save(기능성_다이어트()));
식품_주원료_추가(모든_영양기준_만족_식품, primaryIngredientRepository.save(주원료_소고기()));
식품_주원료_추가(미국_영양기준_만족_식품, primaryIngredientRepository.save(주원료_돼지고기()));
식품_주원료_추가(유럽_영양기준_만족_식품, primaryIngredientRepository.save(주원료_닭고기()));
petFoodRepository.saveAll(List.of(모든_영양기준_만족_식품, 미국_영양기준_만족_식품, 유럽_영양기준_만족_식품));
각 테스트마다 생성하는 게 조금 귀찮긴 하지만 그래도 각 테스트 간 독립성을 보장하며 손쉽게 데이터들을 추가, 제거해 줄 수 있다.
테스트에서 @Transactional
테스트 코드에서 대부분 데이터 롤백의 기능을 사용하기 위해 @Transactional을 많이 사용할 것이다. 하지만, 트랜잭셔널은 롤백 기능 말고도 다양한 기능들이 있기 떄문에 위험성을 인지하고 사용해야 한다. 테스트에 트랜잭셔널을 붙이면 다음과 같은 문제가 생길 수 있다.
- 프로덕션 코드에 트랜잭셔널이 없어도 테스트 통과
- 테스트에서 생성된 트랜잭셔널 범위 안에서 작업했기 때문에 통과할 수 있었음
- DB에서 쿼리가 터져도 테스트 통과
- SQLException이 터지는 코드 작성했다고 가정
- 변경감지로 엔티티 변경
- 변경 감지의 경우 트랜잭션을 커밋할 때 변경 내용을 SQL로 바꾸어 데이터베이스에 반영하는 원리
- 테스트에 적용된 트랜잭셔널은 각 테스트가 끝날 때 롤백하는 것이 기본 설정
- 그렇기 때문에 사실상 SQL 호출이 되지 않음
그렇다면 과연 @Transactional을 사용하지 않고 직접 하나씩 다 지워야 되는 걸까..? 이때, 토비님의 글과 유투브를 보았고 다음과 같은 의견을 주셨다.
@Transactional 대신 tearDown 등에서 db를 클리어 하는 작업은 불가능한 건 아니지만 별로 추천하고 싶지 않습니다. 테스트 이전 상태가 모든 데이터가 다 비어있는 것으로 하기도 하지만, 어느 정도 초기 데이터 상태를 db에 넣고 하는 경우도 많은데, 데이터를 클리어하는 작업에서 이를 정확하게 원복한다는게 롤백 방식을 쓰지 않으면 매우 귀찮고 실수하기 쉽습니다. 초기 데이터가 달라지기라도 하면 모든 db 정리하는 코드를 또 다 고쳐야 하는데, 거기에 오류가 있으면 테스트가 다 깨지거나, 실패해야 할 다음 테스트가 성공하게 만들 수도 있겠죠. 그래서 아주 간단한 경우가 아니면 권장하지 않습니다. 아니면 테스트 하나 수행할 때마다 db 전체를 다 날리고 초기화 하는 작업을 하는 방법도 있긴한데, 애플리케이션이 커지면서 테스트가 매우 느려질테니 결국 테스트를 덜 만들거나 잘 하지 않게 될 겁니다. 단점이 더 많은 거죠.
또한, 스프링 개발팀도 사용을 적극적으로 추천하고 있다고 하고 김영한 님께도 여쭤보았더니 다음과 같은 말을 하셨다고 ㅋㅋㅋ
“그러면 실용성이 너무 떨어지잖아요. 몇가지 조심하면 되는데 그것 때문에 오만가지 불편함을 감수하면서 초가삼간 다 태울 수 없으니…”
그렇다면 어떻게 최대한 예방할 수 있을까?
테스트를 웬만큼 잘 작성해도 애플리케이션 코드를 완벽하게 검증할 수는 없다는 사실을 인식해야 하고, 개발자가 작성하는 테스트, 단위 테스트나 통합 테스트 외에 실제 환경과 유사하게 환경을 구성하고 진행하는 인수 테스트, e2e 테스트, 혹은 http api 테스트 같은 것을 추가로 진행해야 한다고 한다.
또한, 코드에서 발생할 수 있는 전형적인 오류 같은 것들은, 코딩 가이드를 잘 작성해서 따르게 하거나 코드 리뷰에서 확인할 수 있도록 하고, 사용 가능하다면 각종 정적 분석 도구의 힘을 빌어서 어떤 작업을 수행하는 위치에 제한을 걸어주는 등을 통해서 검증이 되도록 해야 한다.
예를 들어 위에서 말한 1번 문제 같은 경우 코드 리뷰에서 잘 확인해 주거나 인수테스트(@Transactional 없는 @SpringBootTest) 등을 통해 실제로 작동되는지 확인을 해줄 수 있을 것 같다.
두 번째 문제 같은 경우 flush를 명시적으로 사용해서 롤백으로 끝나는 테스트가 실제로 쿼리를 DB에 날리도록 해주는 작업이 필요하다.(토비님이 항상 팀원 처음 교육할 때 제일 강조하는 거라고 한다.)
PetFood petFood = new PetFood("이름", "브랜드");
petFoodRepository.save(petFood);
petFood.updateBrand("뉴 브랜드");
entityManager.flush();
이런 문제들을 머릿속에 잘 인식하고 테스트를 작성해야 될 것 같고 그리고 이에 대한 가이드가 매우 중요할 것 같다.
테스트 케이스 추가하기
한 테스트에 많은 경우의 수가 있지만 귀찮아서 전부 안한 경우도 꽤 있던 걸로 기억하는데 어떤 케이스를 넣으면 좋을까? 항상 테스트할 때는 암묵적이거나 아직 드러나지 않은 요구사항이 있는지 계속 염두에 두고 고민해야 한다.
이에 대해서 해피 케이스와 예외 케이스가 있을 수 있는데 말 그대로 요구사항을 만족하는 케이스가 해피 케이스고 만족하지 않는 경우가 예외 케이스이다. 이런 케이스를 테스트할 떄는 경계값을 이용할 수 있다.
예를 들어, 10 이상의 요구사항이 있을 때 해피 케이스를 테스트할 때는 10을, 예외 케이스로는 9를 테스트하는 것이 좋다. 이를 기반으로, 좀 더 꼼꼼한 테스트를 위해 케이스들을 보충하자.
메서드명(or DisplayName) 좀 더 명확하게
// void A를_추가() {
// }
void A를_추가하면_장바구니에_담긴다() {
}
위와 같이 메서드명이 좀 더 길더라도 명사의 나열보다는 문장형이 더욱 좋다. 어떤 상태가 주어졌을 때 어떤 행위를 가했고 어떤 상태변화가 있었다는 결과를 명시할 수 있기 때문에 좀 더 이해하기 쉽다.
// void ~하면_실패한다() {
// }
void ~하면_생성할_수_없다() {
}
또한, 성공, 실패라는 테스트 현상에 집중하지 말고 도메인 관점에서 기술하자.
테스트 환경 통합하기(Context Caching)
스프링 서버가 한번 뜰 때 수행하는 것들이 많아 시간이 어느 정도 걸린다. 이 서버가 뜨는 횟수가 많아진다면 전체 테스트 시간이 굉장히 길어진다. 테스트를 자주 수행하려면 빨라야 되는데, 만약 테스트가 2분 이상씩 걸리면 과연 실행하고 싶을까?
프로파일 환경이라던가 설정, 목빈 같은 띄우는 환경이 조금이라도 달라지면 스프링 서버가 새로 뜨게 된다. 동일한 환경에서 수행될 수 있도록 이런 것들을 조금 모아줘보자.
컨텍스트 캐싱 원리가 궁금하면 다음 문서를 참고하자
우선 기존에 스프링 서버가 몇번 뜨는지 보자.
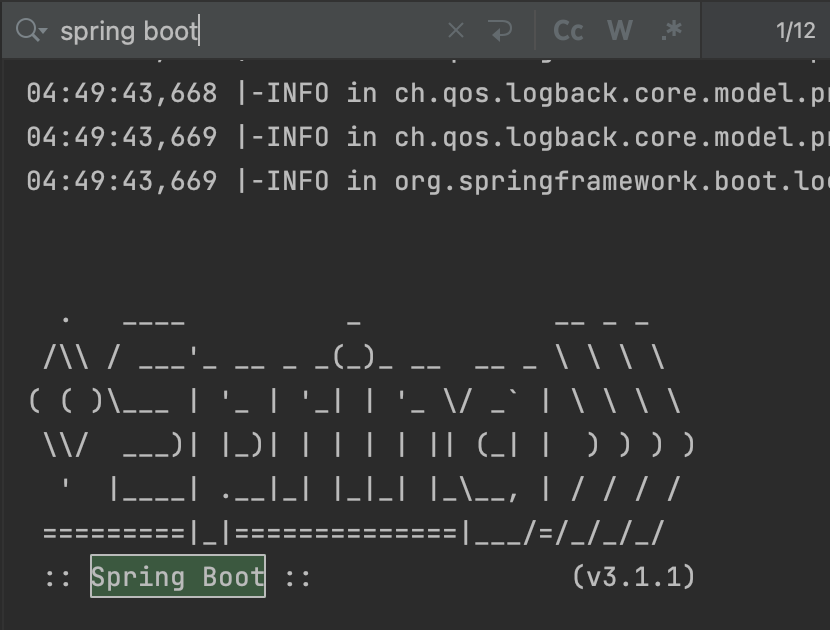
기존에는 12번의 서버가 재실행되고 있었다. 지금 대부분의 테스트들은 AcceptanceTest, ServiceTest, RepositoryTest를 상위에 두고 이를 받도록 하고 있는데도 12번이면 뭔가 어디서 누락되거나 미묘하게 환경이 달라지는 부분이 있다는 것이다.
새로운 스프링 서버가 뜨고 있는 클래스들을 추적해서 굳이 뜰 필요 없는 컨테이너들을 제거해 주거나 동일한 환경이 뜰 수 있도록 세팅을 맞춰주었다. 그렇게 하고 나니깐 5번으로 줄어든 걸 확인할 수 있다.
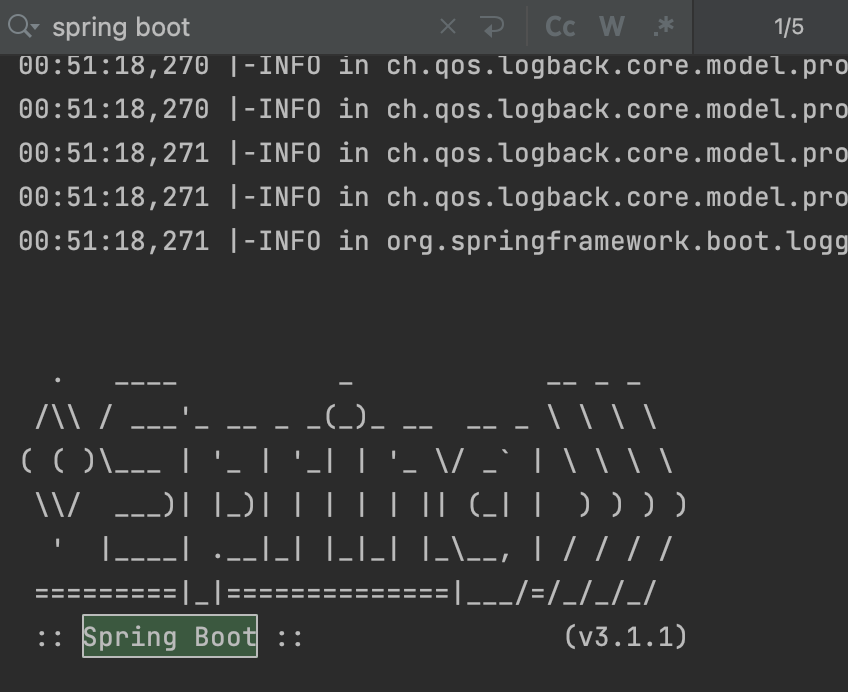
그렇게 하고 두 개의 빌드 시간을 비교해 보았다. 흠.. 지금은 크게 체감이 안되지만 나중에 테스트가 점점 많아지면 더 유의미해질 것 같다.
before

after

*틀린 부분이 있으면 언제든지 말씀해 주시면 공부해서 수정하겠습니다.