ConcurrentHashMap에 대해 알아보자
What is ConcurrentHashMap?
ConcurrentHashMap을 알아보기 전에 왜 ConcurrentHashMap을 사용해야 되는지, 다른 Map 구현체와의 차이에 대해서 살펴보자.
Map 구현체
Map 인터페이스의 구현체로 HashMap, HashTable, ConcurrentHashMap 등이 있다. 이 셋은 과연 어떤 차이가 있을까?
Key, Value에 Null을 허용?
우선 HashMap 같은 경우 key와 value에 null값을 허용한다.
@Test
void hashmap() {
Map<String, String> hashMap = new HashMap<>();
hashMap.put("a", null);
hashMap.put(null, "a");
assertThat(hashMap.get(null)).isEqualTo("a");
assertThat(hashMap.get("a")).isNull();
}
HashTable은 key와 value에 null이 들어가게 되면 NullPointerException이 발생한다.
@Test
void hashtable() {
Hashtable<String, String> hashtable = new Hashtable<>();
assertThrows(NullPointerException.class, () -> hashtable.put(null, "a"));
assertThrows(NullPointerException.class, () -> hashtable.put("a", null));
}
ConcurrentHashMap도 Hashtable과 같이 key와 value에 null이 들어가게 되면 NullPointerException이 발생한다.
@Test
void concurrentHashmap() {
Map<String, String> concurrentHashMap = new ConcurrentHashMap<>();
assertThrows(NullPointerException.class, () -> hashMap.put("a", null));
assertThrows(NullPointerException.class, () -> hashMap.put(null, "a"));
}
동기화 보장?
HashMap 같은 경우 thread-safe 하지 않아 싱글 스레드 환경에서 사용해야 한다. 동기화 처리를 하지 않기 때문에 데이터 탐색하는 속도는 HashTable과 ConcurrentHashMap보다 빠르다. 하지만, 안정성이 떨어지기 때문에 멀티 스레드 환경에서는 사용하면 좋지 않다.
HashTable과, ConcurrentHashMap은 thread-safe 하기 때문에 멀티 스레드 환경에서도 사용할 수 있다. HashTable은 synchronized 키워드를 이용해서 스레드간 동기화 락을 걸어 멀티 스레드 환경에서도 안전하지만, 스레드간 동기화 락은 매우 느리다. 하지만, ConcurrentHashMap 같은 경우 Entry 아이템별로 락을 걸어 성능이 HashTable 보다 빠르기 때문에 멀티 스레드 환경에서는 ConcurrentHashMap을 사용하고 싱글 스레드 환경이 보장된다면 HashMap을 쓰자 (ConcurrentHashMap의 동작 원리는 좀 있다 설명)
//HashTable
public synchronized V put(K key, V value) {
...
}
public synchronized V remove(Object key) {
...
}
...
HashTable과 ConcurrentHashMap의 Lock을 거는 원리를 그림으로 표현하면 다음과 같다.
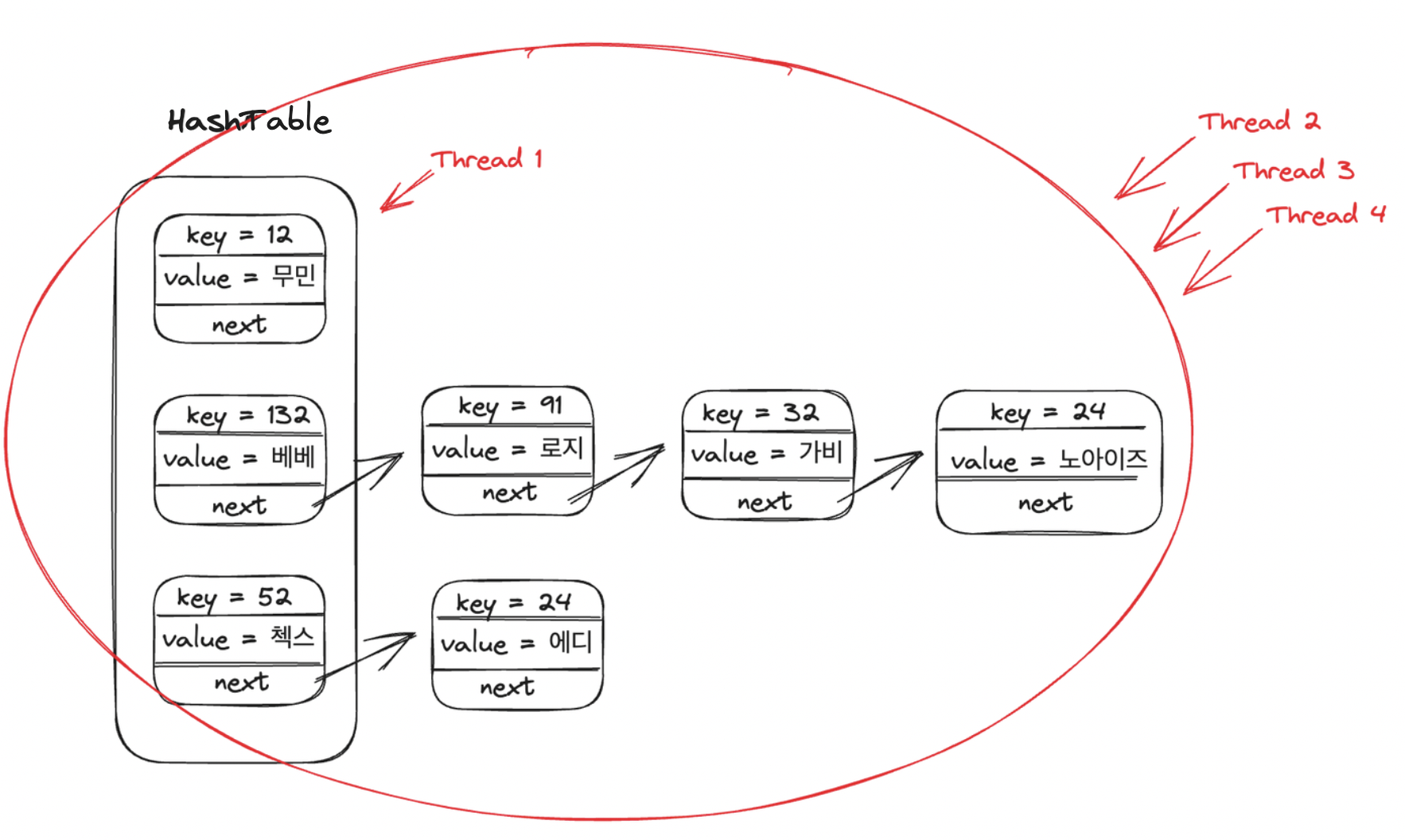
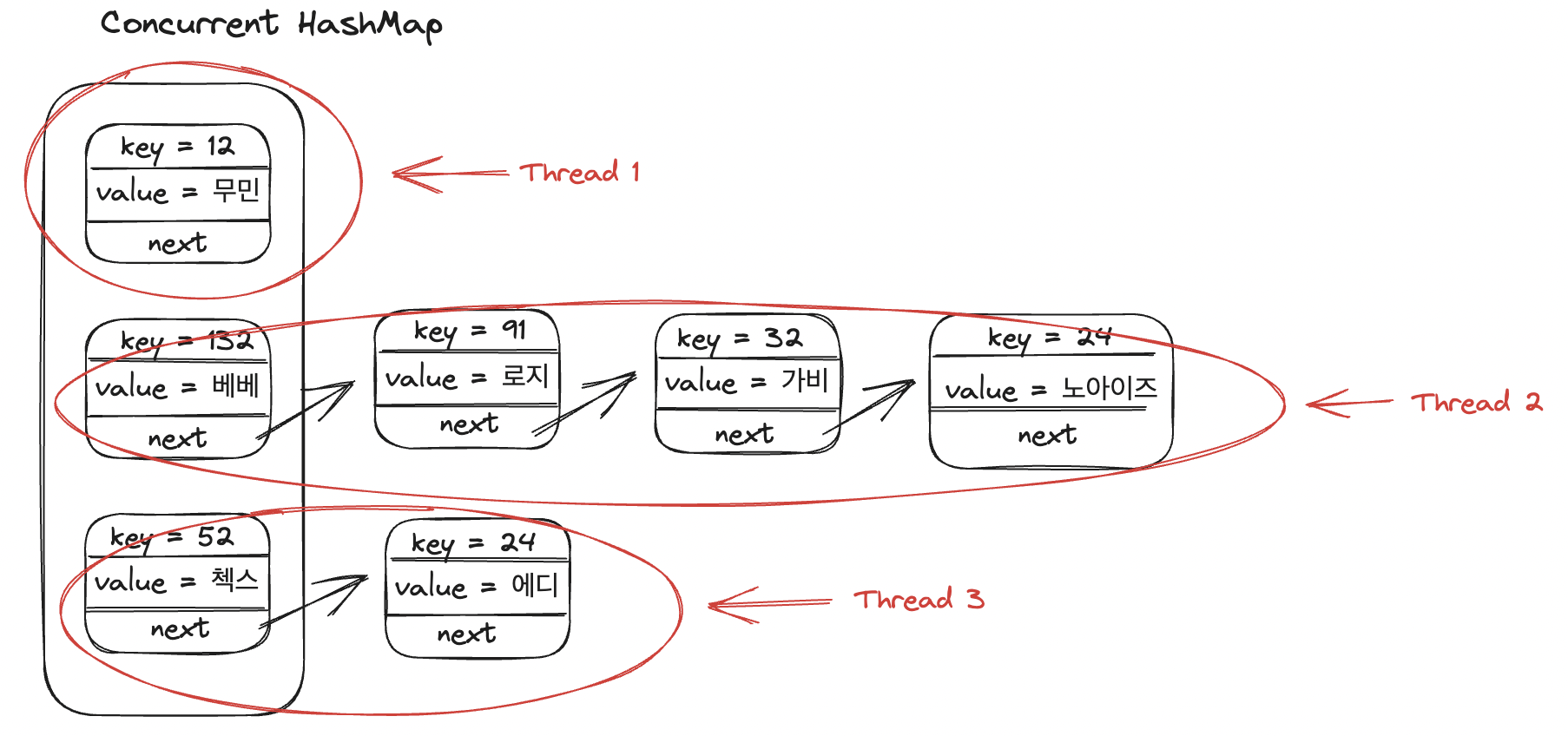
ConcurrentHashMap
자 이제 Concurrent HashMap을 왜 사용해야 되는지에 대해서 알았다. 간단히 요약하자면, Thread safe 하기 때문에 멀티 스레드 환경에서도 안전하고 멀티 스레드 환경에서도 Entry 아이템별로 락을 걸기 때문에 성능이 좋다.
여기서 궁금한 게 그럼 HashTable은 왜 있을까? 이걸 알기 위해서는 나온 순서를 따져봐야 된다. HashTable은 Java 1.0에 등장하여 제공되었는데 속도가 느리고 데이터를 처리할 수 있는 메서드가 부족했다. Java 1.2가 등장하면서 속도가 빠른 HashMap이 제공되었는데 하지만 HashMap은 동기화가 지원되지 않기 때문에 멀티 스레드에서 쓰기 어렵다.
그래서 자바 1.5부터 ConcurrentHashMap이 등장했는데 HashTable 클래스의 단점을 보완하면서도 HashMap 클래스와 다르게 멀티 스레드 환경에서도 사용할 수 있는 클래스다.
+추가적으로 다음과 같이 HashMap을 사용하고도 동기화 문제를 해결할 수도 있다.
Collections.synchronizedMap(new HashMap<>);
ConcurrentHashMap 동작 원리
이번에는 ConcurrentHashMap의 get()과 put() 메서드에 대해서만 알아보겠다. 나머지가 궁금하면 직접 분석해보자!
get()
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
get() 메서드를 보면 synchronized 키워드가 존재하지 않는 걸 볼 수 있다. 즉, get() 메서드에서는 동기화가 일어나지 않고 동시에 put(), remove() 등 메서드와 동시에 수행될 수 있다.
put()
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
위의 코드를 살펴보면 부분적으로 synchronized가 적용된 것을 볼 수 있다. 즉, 항상 동기화 처리가 되는 것이 아니라 해당 조건에서만 동기화 처리가 되기 때문에 성능이 향상된다.
put() 메서드는 크게 else 위아래로 2가지 분기로 나눠지는데 첫 번째 분기가 새로운 노드가 들어갈 배열의 인덱스가 비어 있는 경우이고 두 번째 분기는 이미 기존 노드가 있는 경우이다.
//첫 번째 분기
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break;
}
...
}
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectAcquire(tab, ((long)i << ASHIFT) + ABASE);
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSetObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
첫 번째 분기는 빈 bucket에 노드를 삽입하는 경우 Compare and Swap을 이용하여 lock을 사용하지 않고 새로운 Node를 삽입한다.
Compare and Swap: 비교 및 스왑은 동시 알고리즘을 설계할 때 사용되는 기법으로 변수의 값을 예상 값과 비교하고 값이 같으면 변수의 값을 새로운 값으로 바꾼다.
ConcurrentHashMap의 내부 가변 배열 table을 돌면서 해당 bucket을 가져온다. 해당 bucket이 비어있으면 casTabAt()을 이용해 Node를 담고 있는 volatile 변수에 접근하고 null이면 Node을 생성해 넣는다.
두 번째 분기는 이미 Bucket에 Node가 존재하는 경우 synchronized를 이용해 다른 스레드가 접근하지 못하도록 lock을 걸어 다른 thread가 같은 hash bucket에 접근이 불가능해진다.(여기가 핵심)
//두 번째 분기
...
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
...
현재 f는 위에서 이미 비어있는지 확인을 하고 왔기 때문에 비어있지 않은 bucket을 의미한다. 해당 버킷에서 동일한 Key 이면 Node를 새로운 노드로 바꾼다. 해시 충돌이면 Seperate Chaining이나 TreeNode에 추가한다.
그렇다면 어떻게 동시성을 테스트 해볼 수 있을까?
이번 우테코 톰켓 구현하기 미션에서 SessionManager를 ConcurrentHashMap으로 변경하라는 요구사항이 있었다. 물론 검수가 완료되었으니깐 해당 클래스로 등장했겠지만 처음 써보는 입장에서 ConcurrentHashMap이 동시성을 보장해 주는지 테스트가 하고 싶은 법…
private static final int maxThreads = 10;
private static final HashMap<String, Integer> hashMap = new HashMap<>();
private static final Hashtable<String, Integer> hashtable = new Hashtable<>();
private static final ConcurrentHashMap<String, Integer> concurrentHashMap = new ConcurrentHashMap<>();
private static final Map<String, Integer> synHashMap = Collections.synchronizedMap(new HashMap<>());
@Test
@RepeatedTest(1000)
void concurrencyTest() {
ExecutorService executorService = Executors.newFixedThreadPool(maxThreads);
for (int i = 0; i < maxThreads; i++) {
executorService.execute(() -> {
for (int j = 0; j < 10000; j++) {
String key = String.valueOf(j);
hashMap.put(key, j);
hashtable.put(key, j);
concurrentHashMap.put(key, j);
synHashMap.put(key, j);
}
});
}
executorService.shutdown();
try {
executorService.awaitTermination(Long.MAX_VALUE, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("hashMap size : " + hashMap.size()); // -> 10205
assertThat(hashMap.size()).isNotEqualTo(10000);
System.out.println("hashtable size : " + hashtable.size()); // -> 10000
assertThat(hashtable.size()).isEqualTo(10000);
System.out.println("concurrentHashMap size : " + concurrentHashMap.size()); // -> 10000
assertThat(concurrentHashMap.size()).isEqualTo(10000);
System.out.println("synHashMap size : " + synHashMap.size()); // -> 10000
assertThat(synHashMap.size()).isEqualTo(10000);
}
결과를 보면 HashMap은 동기화가 이뤄지지 않아 size가 올바르지 않게 나오는 걸 확인해 볼 수 있다.
Thread safe한 Map 간 성능 테스트
한 김에 각 Thread safe 한 map들의 성능들은 어느 정도 차이가 나는지 테스트해보자.
@Test
@RepeatedTest(5)
void performanceTest() throws InterruptedException {
Hashtable<Integer, Integer> hashtable = new Hashtable<>();
Map<Integer, Integer> synHashMap = Collections.synchronizedMap(new HashMap<>());
ConcurrentHashMap<Integer, Integer> concurrentHashMap = new ConcurrentHashMap<>();
long hashtableTime = measure(hashtable);
long synHashMapTime = measure(synHashMap);
long concurrentHashMapTime = measure(concurrentHashMap);
System.out.println("hashTableTime = " + hashtableTime);
System.out.println("synHashMapTime = " + synHashMapTime);
System.out.println("concurrentHashMapTime = " + concurrentHashMapTime);
System.out.println();
}
private static long measure(Map<Integer, Integer> map) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(maxThreads);
int count = 200000;
long startTime = System.nanoTime();
for (int i = 0; i < maxThreads; i++) {
executorService.submit(() -> {
for (int j = 0; j < count; j++) {
int value = ThreadLocalRandom.current().nextInt();
map.put(value, value);
map.get(value);
}
});
}
executorService.shutdown();
try {
executorService.awaitTermination(Long.MAX_VALUE, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
long endTime = System.nanoTime();
return (endTime - startTime) / count * maxThreads;
}
스레드 10개와 200,000개의 데이터를 이용해서 성능을 비교하니 다음과 같이 나왔다. 5번 반복한 결과이다. 부분적으로 Lock을 거는 ConcurrentHashMap의 성능이 매우 좋은 걸 볼 수 있다. 이렇게 잘 만든 Java 개발자님들 Respect 🫡
hashTableTime = 54870 synHashMapTime = 61450 concurrentHashMapTime = 37080
hashTableTime = 46170 synHashMapTime = 50840 concurrentHashMapTime = 34470
hashTableTime = 50980 synHashMapTime = 54490 concurrentHashMapTime = 25080
hashTableTime = 57710 synHashMapTime = 56680 concurrentHashMapTime = 24020
hashTableTime = 51490 synHashMapTime = 53030 concurrentHashMapTime = 22930
*틀린 부분이 있으면 언제든지 말씀해 주시면 공부해서 수정하겠습니다.