3계층형 시스템의 흐름(웹 데이터 흐름)
데이터 흐름을 알아보자
3계층형 시스템의 구성도
먼저 3계층형 시스템의 전체 구성을 보면 아래 그림과 같다.
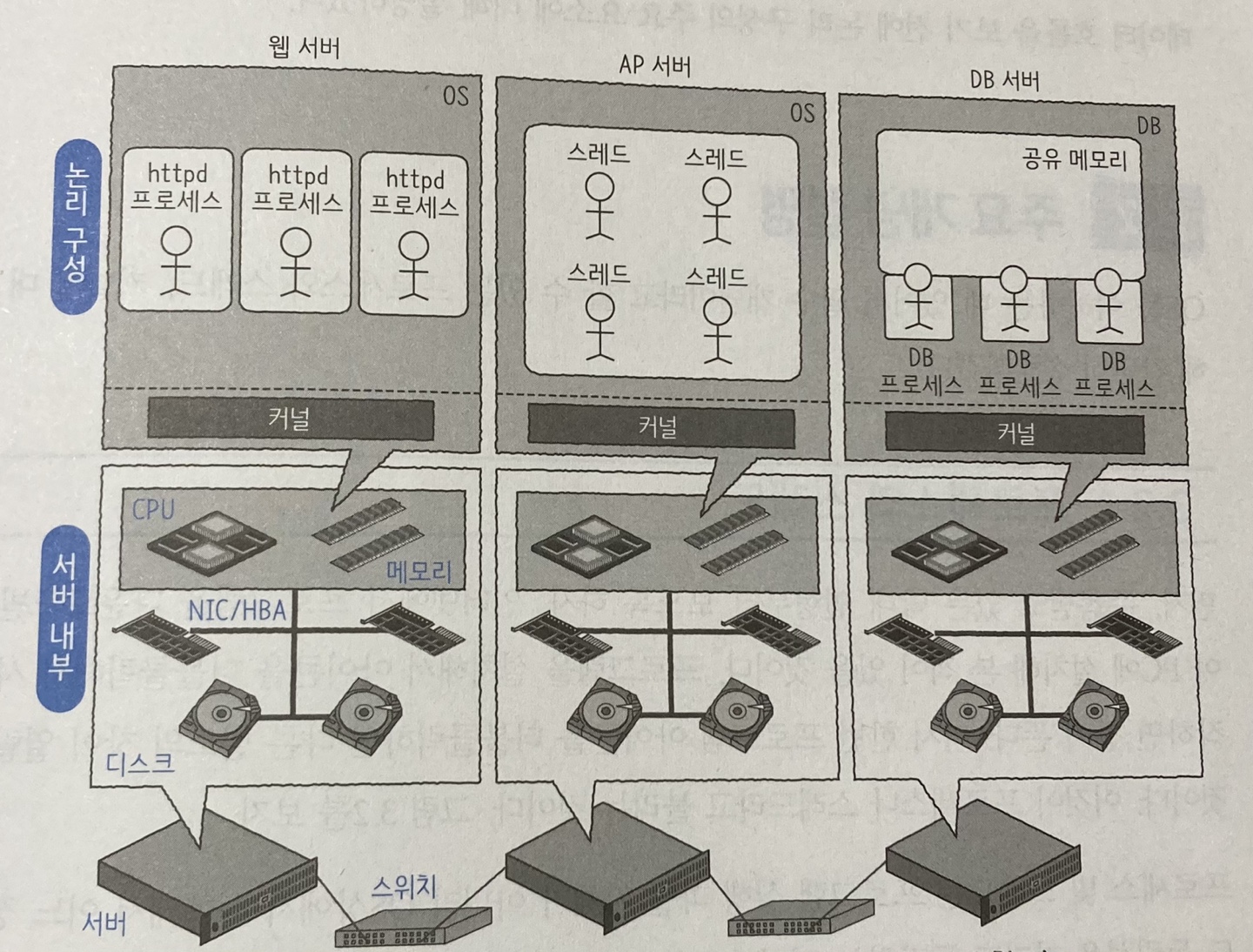
간단하게 살펴보면
- 가장 아래 세 대의 서버가 스위치를 경유해서 연결돼 있다.
- 서버 내부에는 CPU, 메모리, 디스크, NIC/HBA 같은 하드웨어 부품이 있다.
- 그 위에가 CPU와 메모리 영역을 확대한 것으로 이번 글에서 주로 다루는 부분이다.
웹 데이터 흐름
클라이언트 PC부터 웹 서버까지
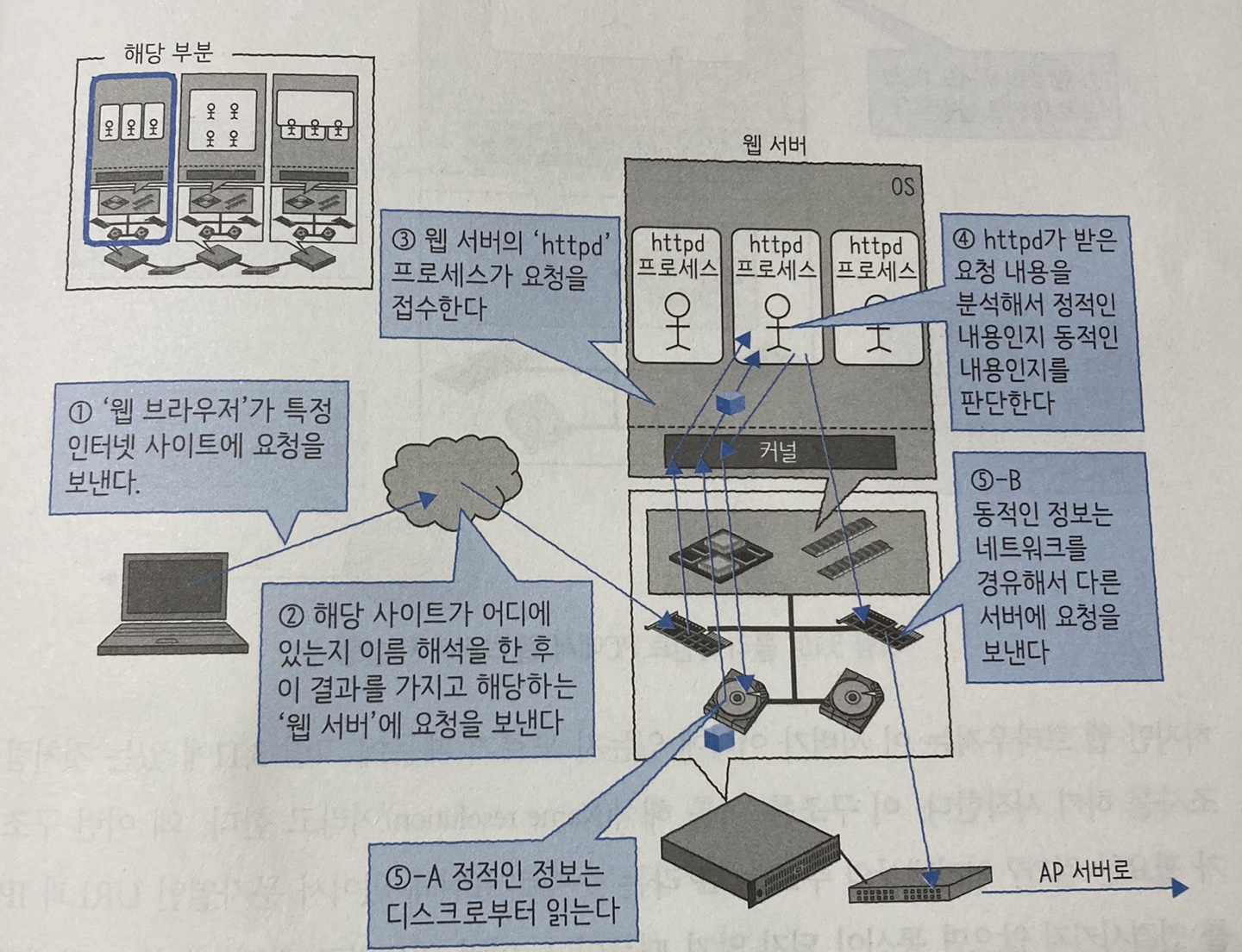
- 웹 브라우저가 요청을 발행
- 이름 해석
- 웹 서버가 요청 접수
- 웹 서버가 정적 콘텐츠인지 동적 콘텐츠인지 판단
- 필요한 경로로 데이터 액세스
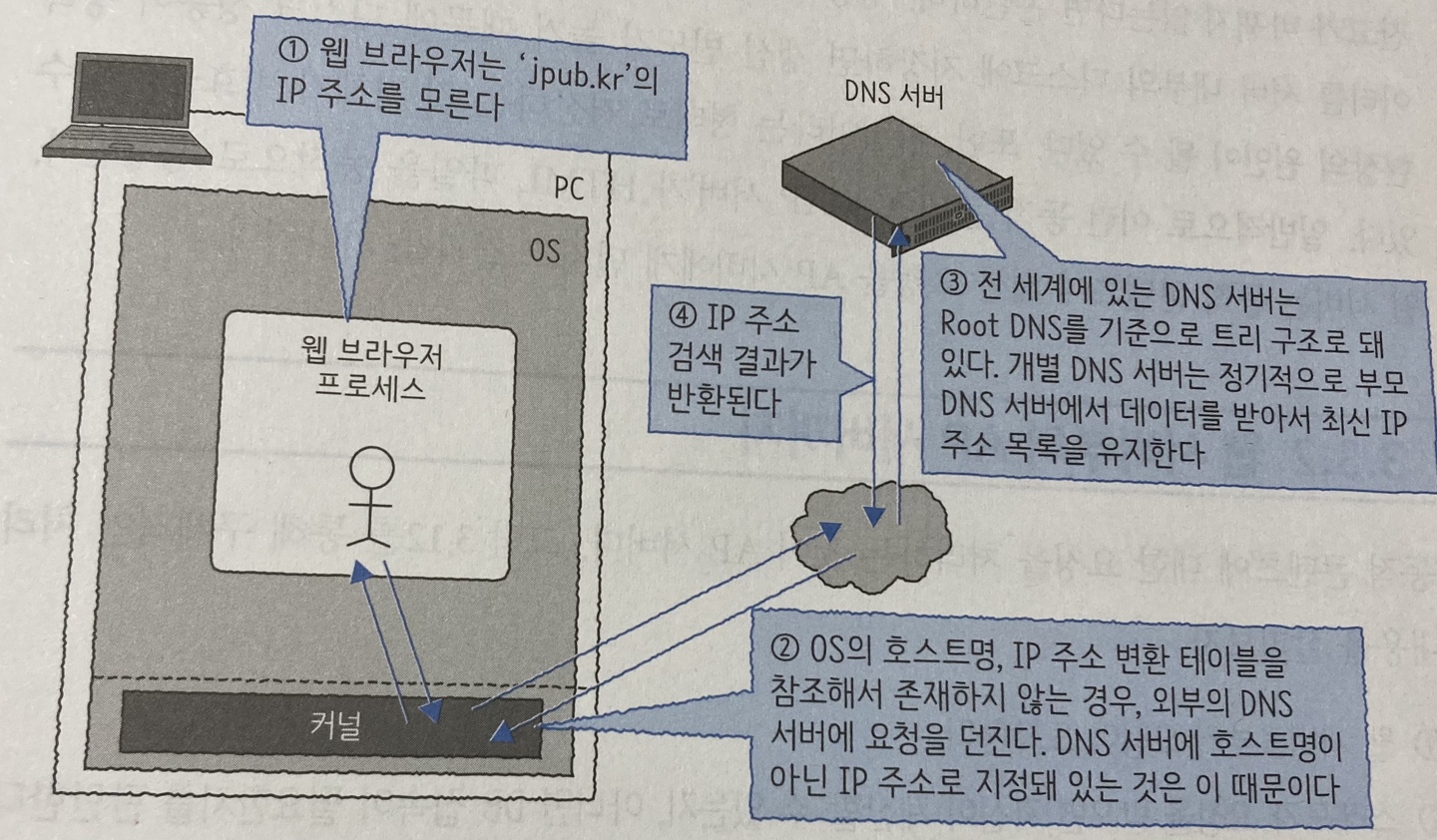
여기서 이름해석이 뭘까? 원하는 웹서버로 요청을 보내기 위해서는 웹서버의 IP 주소를 알아야 되는데 우리는 URL을 입력했기 때문에 그 URL의 맞는 IP를 반환받는 과정이 있어야 한다. 인터넷상의 주소는 ‘IP’라는 숫자로 표현돼 있어서 문자열인 URL과 IP가 연결되어있어야 한다.
이렇게 웹 서버까지 도착하였으면 4번과정을 수행한다. 웹 서버의 역활은 HTTP 요청에 대해 적절한 파일이나 콘텐츠를 반환하는 것이다. 요청에 대한 대답 내용은 HTML 파일이라는 텍스트 데이터나 이미지, 동영상 등의 바이너리 데이터로 구성된다. 이 데이터들은 ‘정적 콘텐츠’와 ‘동적 콘텐츠’로 분류할 수 있다.
‘정적 콘텐츠’란 실시간으로 변경할 필요가 없는 데이터를 가리킨다. 예를들어 회사로고 같은 것이 있다. 이런 데이터 갱신 빈도가 낮은 것은 디스크에 저장해 요청이 있으면 웹 브라우저로 반환한다.
‘동적 콘텐츠’란, 높은 빈도로 변경되는 데이터를 가리킨다. 예를들어 은행 잔고 정보나 쇼핑몰 장바구니 등이 있다. 이런 데이터는 서버 내부 디스크에 저장하면 갱신 빈도가 높아 병목현상의 원인이 될 수 있다. 또한, 파일이라는 형태로 저장하는 것이 비효율적일 수 있기 때문에 이런 동적 컨텐츠는 AP 서버로 요청을 던지고 결과를 기다린다.
웹 서버부터 AP 서버까지
AP 서버는 ‘동적 콘텐츠’에 대한 요청을 처리한다.
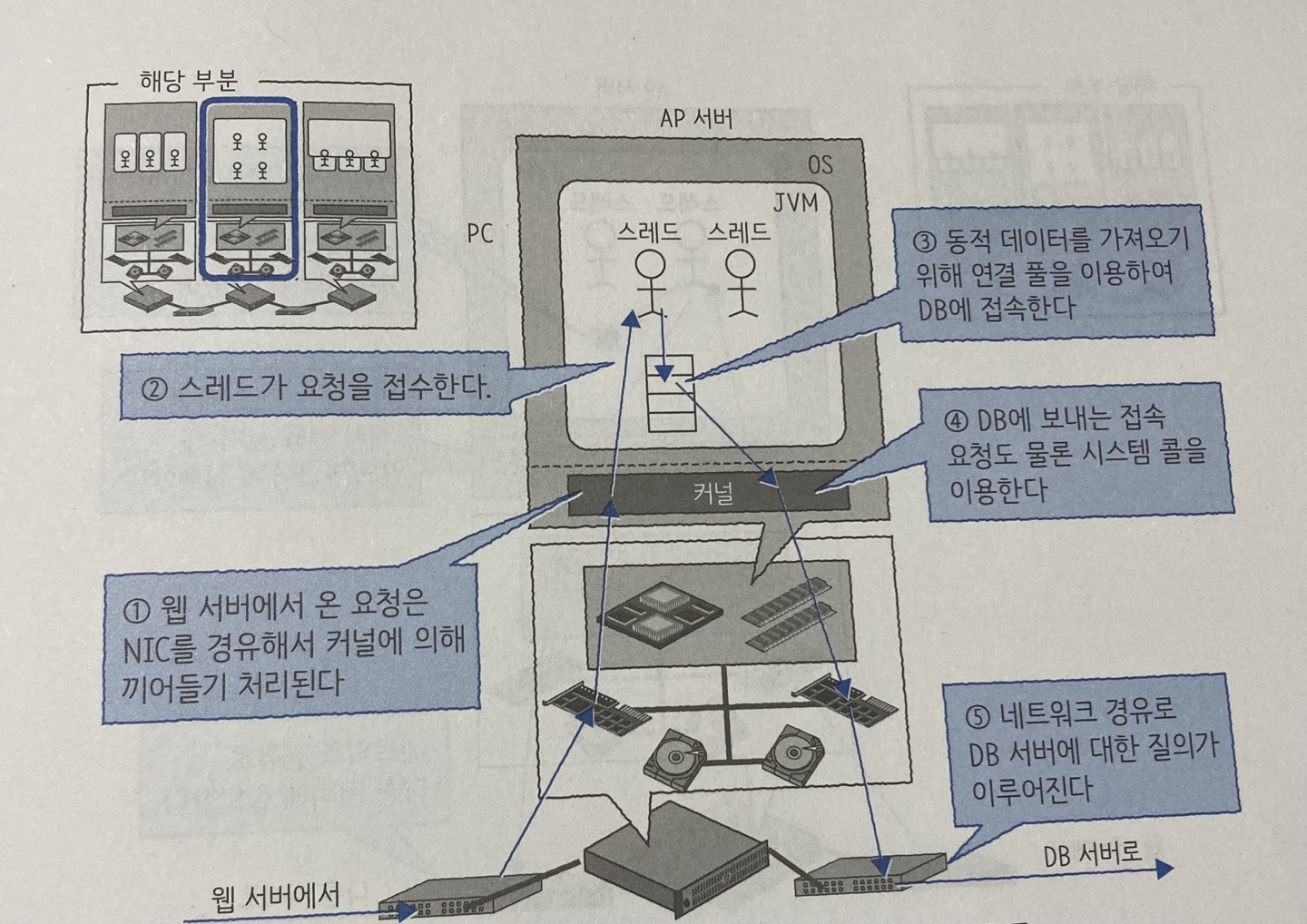
- 웹 서버로부터 요청
- 스레드가 요청을 받으면 자신이 계산할 수 있는지, DB 접속이 필요한지 판단
- DB 접속이 필요하면 연결 풀에 액세스
- DB 서버에 요청
2번을 조금 더 설명하자면 자신이 계산할 수 있다는 것은 ‘1 + 1’ 같은 단순한 요청이고, 데이터 접속이 필요한 요청은 ‘사용자 잔금 정보’ 같은 AP서버가 가지고 있지 않은 정보이다.
데이터가 필요하면 DB 서버에 접속하는 것이 일반적이지만 항상 효율적이라 할 수 없다. 규모가 작고 갱신 빈도가 낮은 정보는 캐시로 저장해 두었다가 반환하는 것이 좋다.
AP 서버부터 DB 서버까지
DB 서버에서 요청을 접수한다. 요청은 SQL이라는 언어 형태로 이루어지고 이 SQL을 해석해서 데이터 액세스 방식을 결정하고 필요한 데이터만 가져오는것이 데이터베이스의 역활이다.
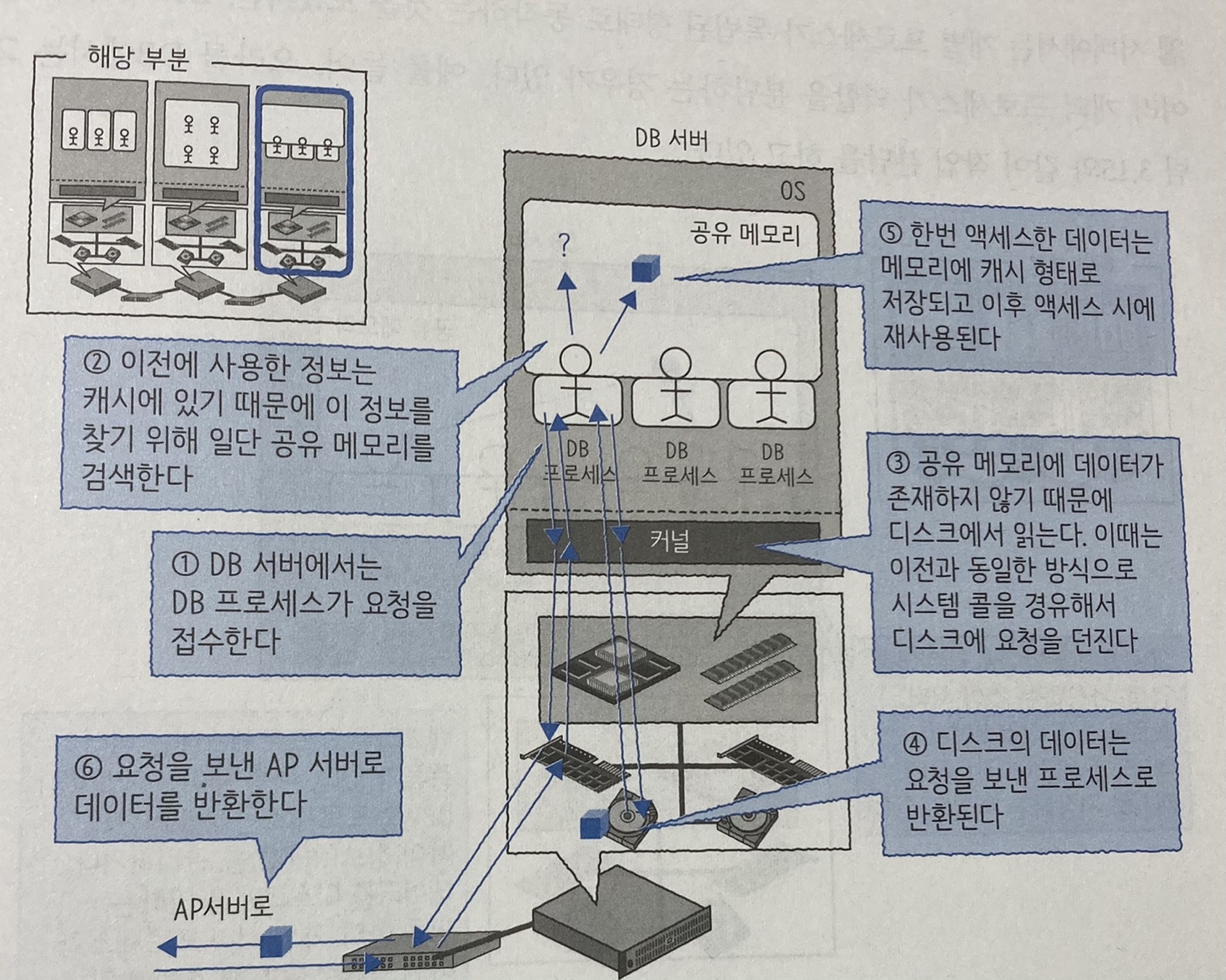
- AP서버로부터 요청
- 프로세스가 요청을 접수하고 캐시가 존재하는지 확인
- 캐시에 없으면 디스크에 액세스
- 디스크가 데이터를 반환
- 데이터를 캐시 형태로 저장
- 결과를 AP 서버에 반환
앞의 그림들에서는 DB 서버의 디스크 액세스 부분이 갼략화되어 있어서 많은 기업형 시스템의 실정이 잘 반영돼 있지 않았다. 실제로는 DB 서버 내부 디스크는 이중화 관점에서 뒤떨어져 직접 사용하는 경우는 드물고 대부분 아래 그림처럼 별도 저장 장치를 이용한다.
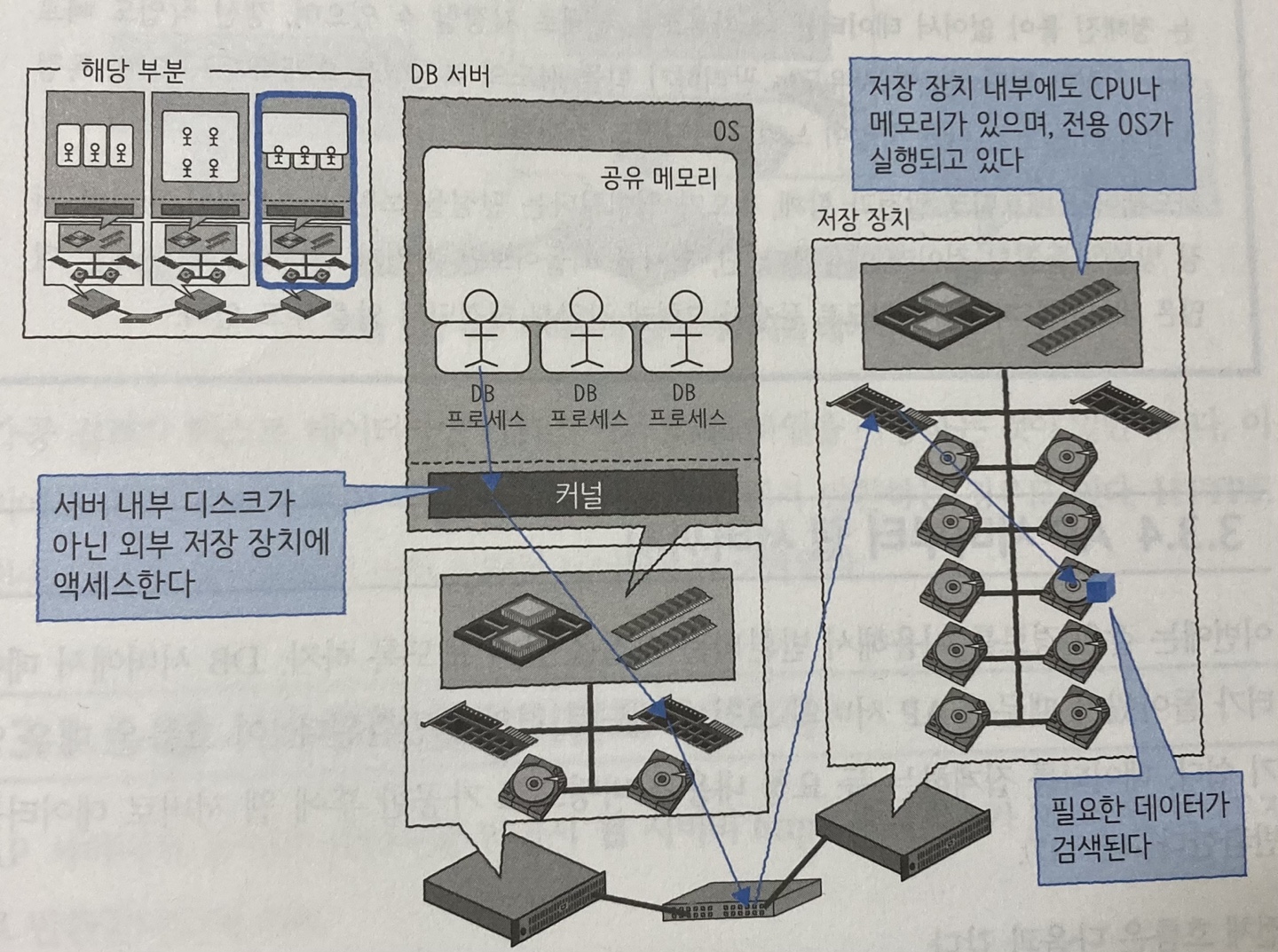
저장 장치에는 다수의 디스크가 설치돼 있다. 하지만 본질적인 구조는 지금까지 등장한 웹 서버, AP 서버, DB서버와 큰 차이가 없다. 대량의 데이터에 고속 액세스하기 위한 전용 서버라고 생각하면 된다.
AP서버부터 웹 서버까지
이번에는 다시 같은 경로를 이용해 반환되는 과정을 보자. DB 서버에서 AP 서버의 요청 스레드로 결과가 반한된다. 이 데이터를 가공한 후에 웹 서버로 데이터를 반환한다.
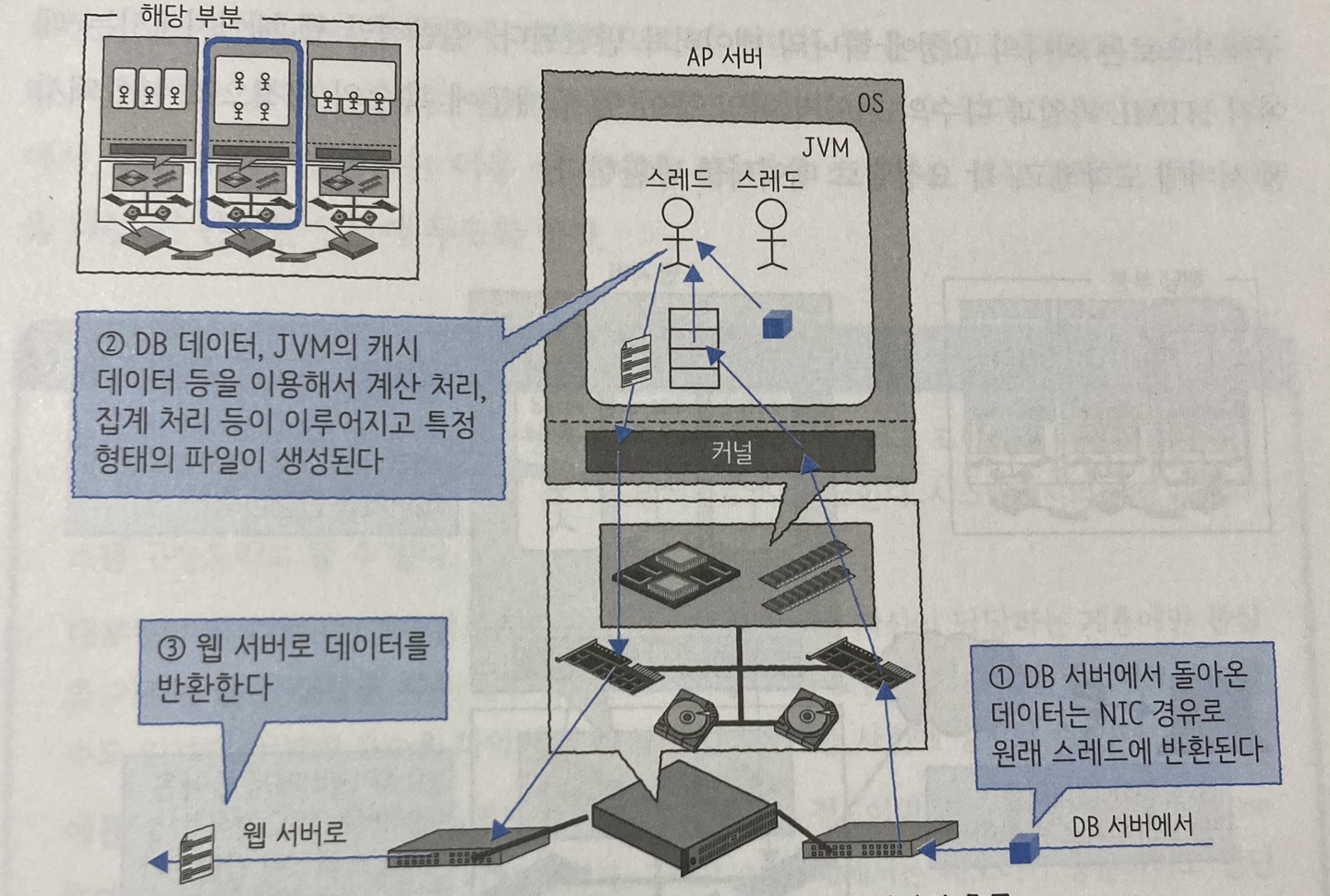
- DB 서버로부터 데이터가 도착
- 스레드가 데이터를 가공한 후 파일 데이터 생성
- 결과를 웹 서버로 반환
가공 결과가 텍스트 데이터라면 HTML이나 XML 파일을 사용하는 것이 일반적이고 이외에 바이너리 데이터를 생성해서 반환하는 경우도 있다. HTTP로 전송 가능한 데이터라면 어떤 형태이든 상관없다.
웹 서버부터 클라이언트 PC까지
AP 서버에서 반환된 데이터를 받아 httpd 프로세스가 PC의 웹 브라우저로 그대로 반환
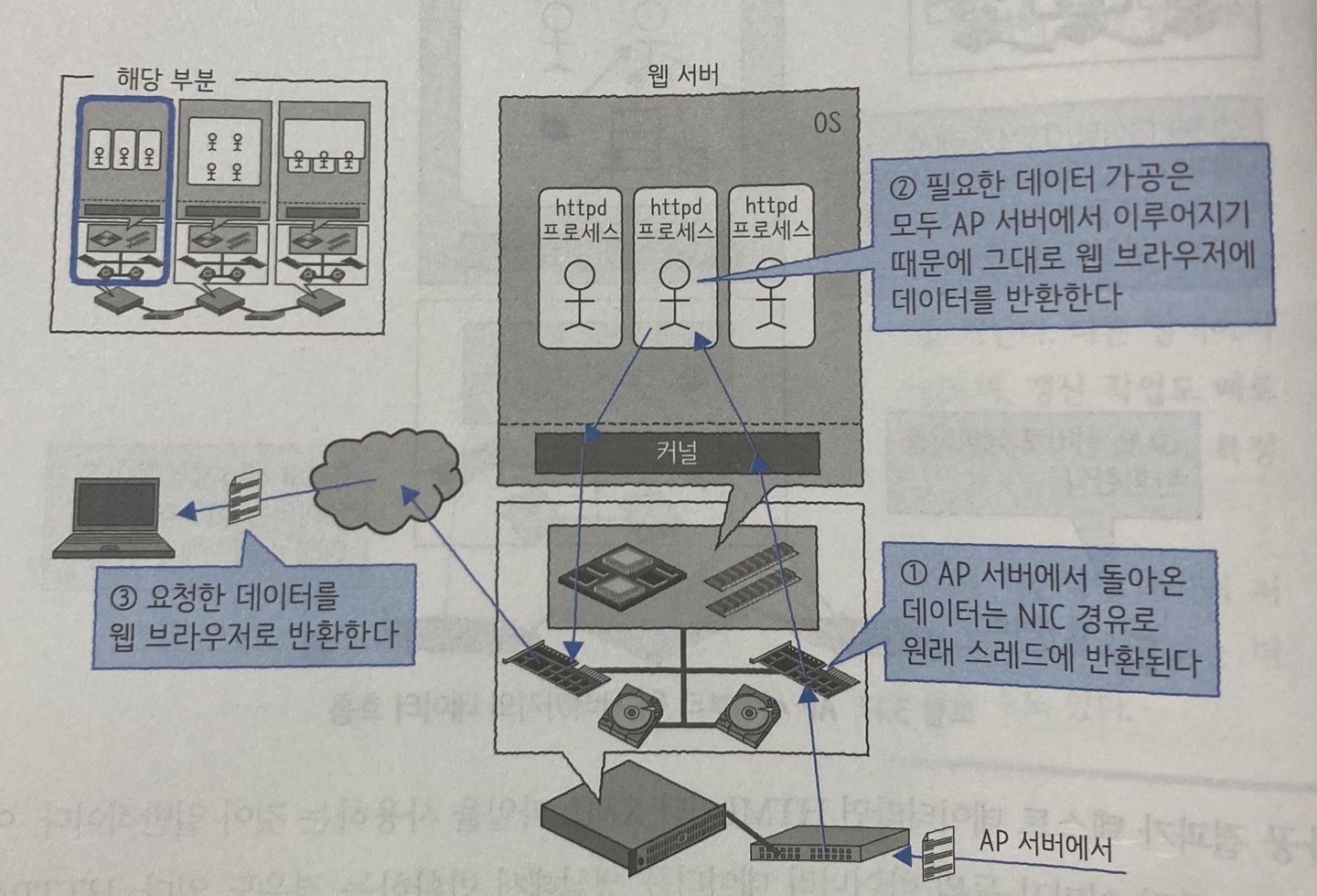
- AP 서버로부터 데이터 도착
- 프로세스는 받은 데이터를 그대로 반환
- 결과가 웹 브라우저로 반환되고 화면에 표시
웹 데이터의 흐름 정리
각 서버의 동작은 다르지만 몇가지의 공통점이 있다. 프로세스나 스레드가 요청을 받고 도착한 요청을 파악해서 필요에 따라 별도 서버로 요청을 보낸다. 그리고 도착한 요청에 대한 응답을 한다. 3계층 시스템에서는 사용자 요청이 시작점이 돼서 해당 요청이 다양한 서버로 전달된다. 자신이 할 수 없는 처리는 다음 서버로 역활을 넘긴다는 것이다. 3계층이라 하고 있지만, 실제로는 대부분 더 많은 계층을 사용하고 있다.
참고: 그림으로 공부하는 IT 인프라 구조
*틀린 부분이 있으면 언제든지 말씀해 주시면 공부해서 수정하겠습니다.