외부 서비스로부터 영향 범위 최소화하기 (1)
Minimize impact from external services
외부 서비스는 우리가 통제할 수 없는 영역이기 때문에 많은 고민이 필요하다. 최근에 실무 쪽에 관심이 많아지면서 현업에서는 어떻게 외부 서비스와의 의존성을 관리하고 영향을 최소화하고 있는지 궁금했다. 두 개의 포스팅으로 나눠서 이번 글에는 외부 서비스와의 영향을 최소화하는 방법에 알아보고 다음 글에서는 여러 서비스에서 트랜잭션을 어떻게 보장해줄 수 있는지에 대해 알아보자.
외부 영향 최소화하기
1. 의존성 제거
- 처음에 외부 시스템을 연동할 때는 해당 연동이 꼭 필요한지 고민
- 외부 시스템의 안정성을 신뢰할 수 있을지, 연동을 통해 얻고자 하는 목적이 뚜렷한지, 리스크를 감수할 만큼의 가치가 있는지
- 이미 연동해서 사용 중인 시스템이더라도 지속적으로 적합성을 살펴보는 관심 필요
- 서비스가 커지고 구조가 변경되면 외부 시스템을 통한 이득은 변하지 않지만 리스크가 더 커지는 경우가 있고, 필요한 곳이 더 늘어나면서 연동 대상이 변경되거나 내부에서 직접 구현하는 경우도 있음
- 이런 변화를 지켜보다가 적절한 시점에 의존성을 제거해 주는 것이 좋음
2. 벤더 이중화
- 동일한 기능을 제공하는 여러 벤더 사가 존재하는 경우 벤더 이중화를 통해서 장애를 회피해 볼 수 있음
- 이중화를 한 경우라도, 일정 비율을 두고 양쪽 벤더를 모두 사용할 수 있도록 연동하는 것을 추천
- 한 쪽만 사용하다 전환했을 때 반대편이 정상적으로 동작하지 않아 장애가 해소되지 않을 수도 있기 때문에 양쪽과 상시로 트래픽을 주고 받어 연동 상태를 늘 체크하는 것이 좋음
3. 장애 격리
- 여러 이유(비용이 비싸거나, 대체 벤더가 없거나)로 이중화 불가능한 외부 시스템도 당연히 존재
- 이런 경우 외부 시스템 장애가 연동과 관련 없는 부분으로 전파되지 않도록 장애를 격리하는 것이 중요
- 특정 기능이 일부 동작하지 않거나 기능이 저하되더라도 사용자가 최소 기능을 사용할 수 있도록 제공하는 것이 핵심
4. 미작동 감내
- 위에서 설명한 1, 2, 3 방법으로도 장애 회피가 불가능한 경우가 바로 AWS, GCP 같은 클라우드 서비스
- 이런 경우 외부 시스템의 장애를 감내하고 장애 상황을 빠르게 인지할 수 있도록 모니터링을 강화하고 해당 서비스 담당 부서에 빠르게 확인할 수 있는 핫라인 조치 필요
장애 격리를 위한 3가지 방법
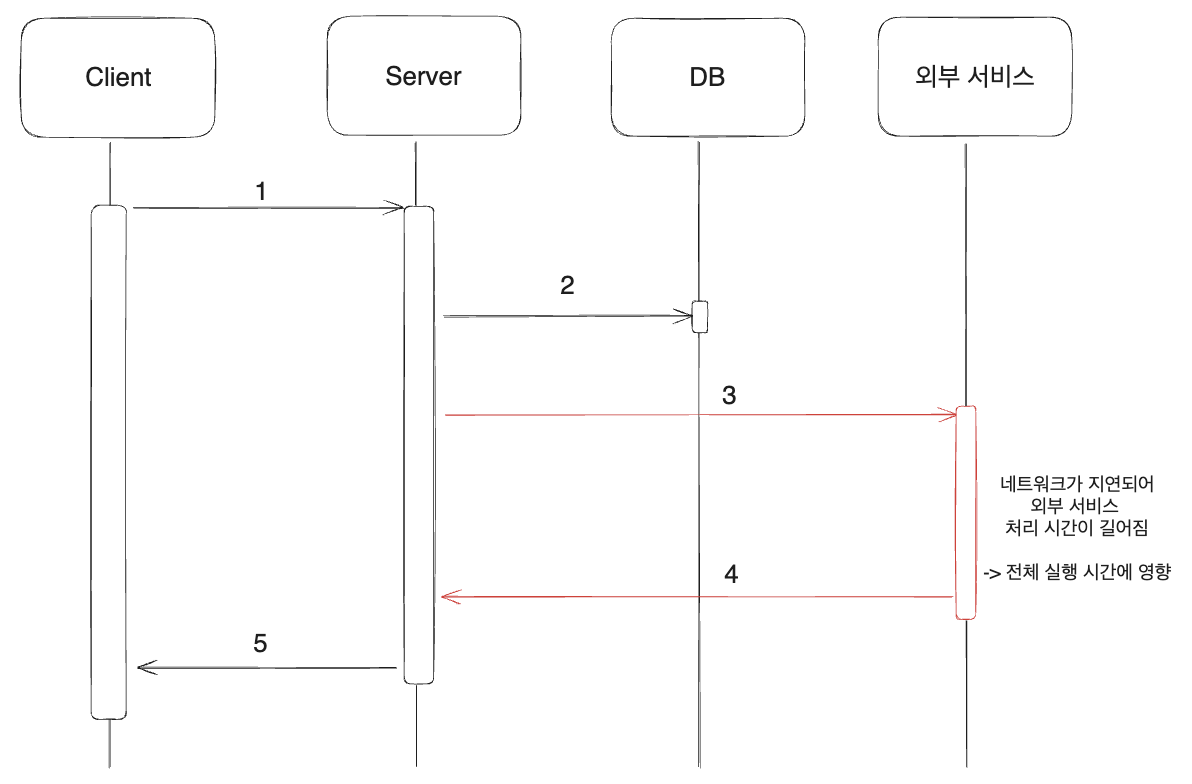
외부 서비스와 연동을 하다가 외부 서비스에서 처리 시간이 길어지면 전체 실행 시간에 영향이 가고 그에 따라 성능 저하가 있을 수 있다. 예를 들어, 서버 쓰레드 풀이 5개인 서비스가 있다고 가정해 보자.
- 외부 연동이 정상적으로 처리되어서 0.1초 + 나머지 시간 0.1초 => 평균 응답 시간 0.2초
- 1개 쓰레드가 초당 5개 요청을 처리
- 5개 쓰레드가 초당 25개 요청 처리로 25 TPS
- 외부 연동이 지연되어 0.9로 증가 + 나머지 시간 0.1초 => 평균 응답 시간 1초
- 1개 쓰레드가 초당 1개 요청 처리
- 5개 쓰레드가 초당 5개 요청 처리로 5 TPS
결과적으로 1/5의 성능이 나오게 되어 25개의 요청이 들어오게 되면 원래 1초 만에 응답을 받던 클라이언트가 5초 만에 응답받게 된다.
타임 아웃
RestTemplate의 타임아웃 기본 값에는 제한이 없다. 이 경우 동시에 대기하는 외부 연동 개수가 많아질수록 내 서비스는 점점 느려진다는 걸 뜻한다. 최악의 경우 모든 쓰레드가 대기 상태에 빠져 다른 클라이언트 요청에 응답할 쓰레드가 남아있지 않게 되기 때문에 반드시 타임아웃 설정이 필요하다.
일반적으로 Connection Timeout과 Read Timeout을 1초에서 5초 이내로 설정해 줄 수 있는데 상황에 따라 달라질 수 있기 때문에 근거 있는 기준이 필요하다. (ex. 한 번의 패킷 유실 정도는 재전송을 통해 해결할 수 있는 수준의 타임아웃) 더 자세한 건 다음 블로그를 참고하면 좋을 것 같다.
벌크 헤드
외부 연동 서비스가 많은 경우 특정 서비스에 장애가 발생하면 전체에도 영향이 가게 된다.
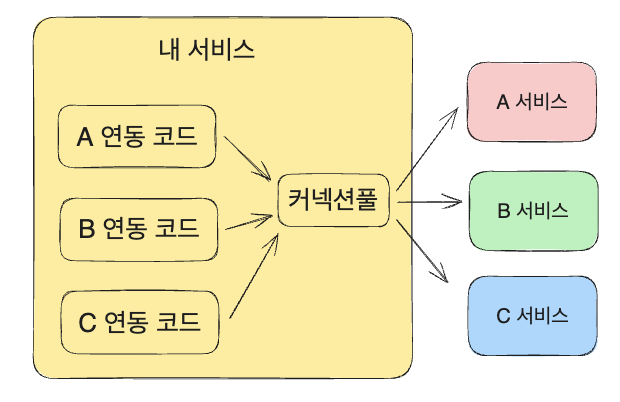
위와 같이 커넥션풀을 공유하면서 A, B, C 서비스에 대해 연동을 했다고 가정해 보자. A 서비스가 장애가 생겨서 응답 시간에 지연이 발생하면 풀에 남은 사용 가능한 커넥션이 줄면서 풀에서 커넥션을 구하는 대기시간이 증가하고 B, C 서비스에 대한 연동도 같이 대기하게 된다.
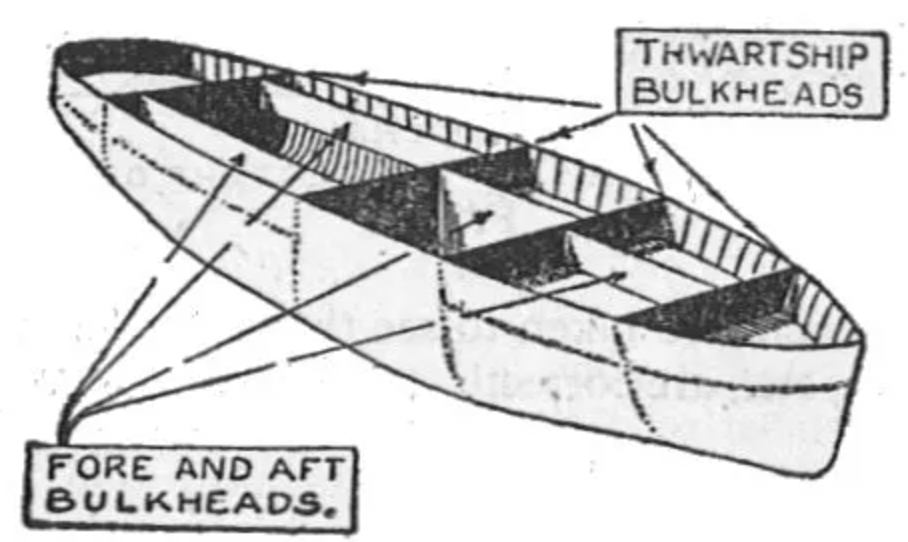
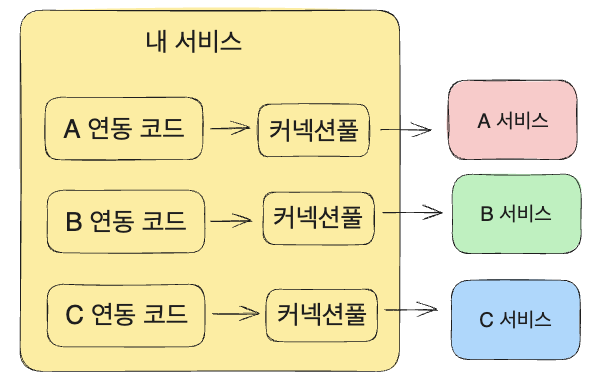
벌크헤드는 격벽을 치는 것을 뜻하며 배에서 4개의 격벽을 치는 것으로부터 유래되었다. 각자의 구역에서 무슨 일이 있더라도 다른 곳에서는 영향이 덜 하도록. 이를 서비스에도 적용하여 기능/서비스/클라이언트마다 자원을 분리해서 사용할 수 있다. 즉, 다음과 같이 외부 서비스마다 별도 커넥션풀을 사용하는 것이다. 그2023-11-30-better-external-api.md렇게 하면 A 서비스와 연동이 느려져도 B, C 서비스 연동에서의 영향은 감소시킬 수 있다.
서킷 브레이커
외부 시스템 장애가 지속되면 외부 서비스가 비정상임에도 내 서비스에서 계속해서 요청을 보낼 것이다. 그러면 응답 시간도 계속 느려지고 처리량도 감소한다. 이때 서킷 브레이커를 적용하면 내 서비스의 응답 시간과 처리량을 일정하게 유지할 수 있다.
서킷 브레이커는 오류 지속 시 일정 시간 동안 기능 실행을 차단한다. 즉, 기능을 실행하지 않고 바로 에러를 응답한다. 이렇게 빠른 실패(fail fast)를 함으로 써 외부 서비스의 장애로 인한 영향을 차단하고 응답 시간이 증가하거나 처리량이 감소하는 증상을 어느 정도 완화할 수 있다.
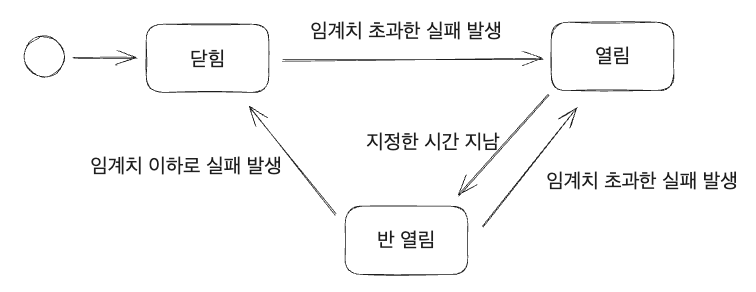
서킷 브레이커의 기본적인 동작 방식을 보자. 처음 상태는 서킷 브레이커가 닫혀있다.(요청을 통과시킨다는 것) 그러다 임계치를 초과한 실패가 발생하면 서킷 브레이커가 열리게 된다. 열리면 외부 api를 호출하지 않고 바로 에러를 리턴 한다. 일정 시간 동안 열린 상태를 유지하다가 시간이 지나면 반정도 연다.(half open) 반 정도 열게되면 다시 외부 api를 호출하고 제대로 작동하는지 확인해본다. 확인해서 다시 임계치를 초과한 실패가 발생하면 열리고 만약 임계치 이하로 실패가 발생하게되면 닫히게 된다.
이번 글은 여기서 끊고 다음 포스팅에서 여러 서비스에서 트랜잭션을 어떻게 보장해줄 수 있을지 알아보도록 하겠습니다.
참고:
*오타가 있거나 피드백 주실 부분이 있으면 편하게 말씀해 주세요.